数据分析
数据分析流程
- 业务调研
- 明确目标
- 数据准备:数据抽取、数据清洗转换、数据加载
- 特征处理
- 特征向量化。数值特征、类别、文本、统计
- 文本特征处理:分词(Tokenization)、去停用词(StopWordsRemover)、词稀疏编码(StringIndexer)
- 特征预处理:特征归一化(StandardScaler、MinMaxScaler、MaxAbsScaler)、正则化(Normalizer)、二值化(Binarizer)
- 模型训练与评估
- 输出结论
数据分析基本方法
- 汇总统计
- 相关性分析
- Pearson
- Spearman
- 分层抽样
- 假设检验:皮尔森卡方检验 chiSqTest
1 | * download url: https://snap.stanford.edu/data/loc-gowalla.html |
一层神经元的Cifar二分类
将反向传播的
https://www.cnblogs.com/charlotte77/p/5629865.html
1 | import pickle |
卷积神经网络
最普通的
就计算图变了1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
x = tf.placeholder(tf.float32, [None, 3072])
y = tf.placeholder(tf.int64, [None])
# [None], eg: [0,5,6,3] 把一维向量转换为三通道的一个图片形式
x_image = tf.reshape(x, [-1, 3, 32, 32])
# 32*32 交换通道
x_image = tf.transpose(x_image, perm=[0, 2, 3, 1])
# conv1: 神经元图, feature_map, 输出图像
conv1 = tf.layers.conv2d(x_image,
32, # output channel number
(3,3), # kernel size
padding = 'same',
activation = tf.nn.relu,
name = 'conv1')
# 图像大小变为16 * 16
pooling1 = tf.layers.max_pooling2d(conv1,
(2, 2), # kernel size
(2, 2), # stride
name = 'pool1')
conv2 = tf.layers.conv2d(pooling1,
32, # output channel number
(3,3), # kernel size
padding = 'same',
activation = tf.nn.relu,
name = 'conv2')
# 8 * 8
pooling2 = tf.layers.max_pooling2d(conv2,
(2, 2), # kernel size
(2, 2), # stride
name = 'pool2')
conv3 = tf.layers.conv2d(pooling2,
32, # output channel number
(3,3), # kernel size
padding = 'same',
activation = tf.nn.relu,
name = 'conv3')
# 4 * 4 * 32
pooling3 = tf.layers.max_pooling2d(conv3,
(2, 2), # kernel size
(2, 2), # stride
name = 'pool3')
# [None, 4 * 4 * 32] 全连接 (扁平化)
flatten = tf.layers.flatten(pooling3)
y_ = tf.layers.dense(flatten, 10)
loss = tf.losses.sparse_softmax_cross_entropy(labels=y, logits=y_)
# y_ -> sofmax
# y -> one_hot
# loss = ylogy_
# indices
predict = tf.argmax(y_, 1)
# [1,0,1,1,1,0,0,0]
correct_prediction = tf.equal(predict, y)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float64))
VGG
就是多了一些卷积层
视野域:
- 2个33 = 1个55
- 2层比1层多一次非线性变换
- 参数降低28%
VGG由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooling(最大化池)分开,所有隐层的激活单元都采用ReLU函数。
1、结构简洁
VGG由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooling(最大化池)分开,所有隐层的激活单元都采用ReLU函数。
2、小卷积核和多卷积子层
VGG使用多个较小卷积核(3x3)的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合/表达能力。
小卷积核是VGG的一个重要特点,虽然VGG是在模仿AlexNet的网络结构,但没有采用AlexNet中比较大的卷积核尺寸(如7x7),而是通过降低卷积核的大小(3x3),增加卷积子层数来达到同样的性能(VGG:从1到4卷积子层,AlexNet:1子层)。
VGG的作者认为两个3x3的卷积堆叠获得的感受野大小,相当一个5x5的卷积;而3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。这样可以增加非线性映射,也能很好地减少参数(例如7x7的参数为49个,而3个3x3的参数为27)
3、小池化核
相比AlexNet的3x3的池化核,VGG全部采用2x2的池化核。
4、通道数多
VGG网络第一层的通道数为64,后面每层都进行了翻倍,最多到512个通道,通道数的增加,使得更多的信息可以被提取出来。
5、层数更深、特征图更宽
由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,控制了计算量的增加规模。
6、全连接转卷积(测试阶段)
这也是VGG的一个特点,在网络测试阶段将训练阶段的三个全连接替换为三个卷积,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入,这在测试阶段很重要。
1 | x = tf.placeholder(tf.float32, [None, 3072]) |
ResNet
假设现有一个比较浅的网络(Shallow Net)已达到了饱和的准确率,这时在它后面再加上几个恒等映射层(Identity mapping,也即y=x,输出等于输入),这样就增加了网络的深度,并且起码误差不会增加,也即更深的网络不应该带来训练集上误差的上升。而这里提到的使用恒等映射直接将前一层输出传到后面的思想,便是著名深度残差网络ResNet的灵感来源。
这种残差跳跃式的结构,打破了传统的神经网络n-1层的输出只能给n层作为输入的惯例,使某一层的输出可以直接跨过几层作为后面某一层的输入,其意义在于为叠加多层网络而使得整个学习模型的错误率不降反升的难题提供了新的方向。
1 | def residual_block(x, output_channel): # 输出通道数翻倍 |
InceptionNet
分组卷积
(1)参数太多,如果训练数据集有限,很容易产生过拟合;
(2)网络越大、参数越多,计算复杂度越大,难以应用;
(3)网络越深,容易出现梯度弥散问题(梯度越往后穿越容易消失),难以优化模型。
Inception V1
通过设计一个稀疏网络结构,但是能够产生稠密的数据,既能增加神经网络表现,又能保证计算资源的使用效率。
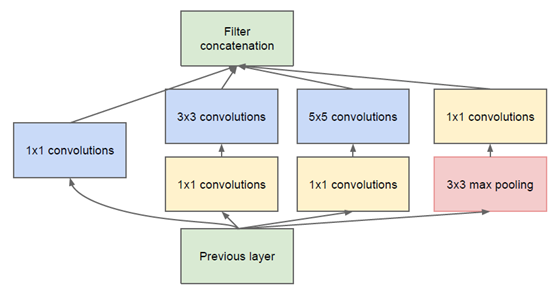
1 | def inception_block(x, |