构造函数 析构函数
析构函数和构造函数是一对。构造函数用于创建对象,而析构函数是用来撤销对象。
内联函数
inline
1.内联函数在运行时可调试,而宏定义不可以;
2.编译器会对内联函数的参数类型做安全检查或自动类型转换(同普通函数),而宏定
义则不会;
3.内联函数可以访问类的成员变量,宏定义则不能;
4.在类中声明同时定义的成员函数,自动转化为内联函数。
C语言中switch 的查找实现原理
- if…else结果的查找
当case语句是小于3句的时候,switch语句底层的实现和if…else的实现方式相同。 - 线性查找
当case语句大于等于4的时候,且每两个case之间产生的间隔之和不超过6时,就按线性结构查找。即,如下图的汇编里面的jmp dword ptr [edx*4+11B1428h]该指令里面的11B1428h地址里面,其存放着各个case语句的首地址。由于内存中下标是从0开始的,因此,通过对其进行减一操作,在判断其是否大于11B1428h地址的数组长度,如果大于直接跳出,否则通过计算直接定位到该数组上的地址进行跳转。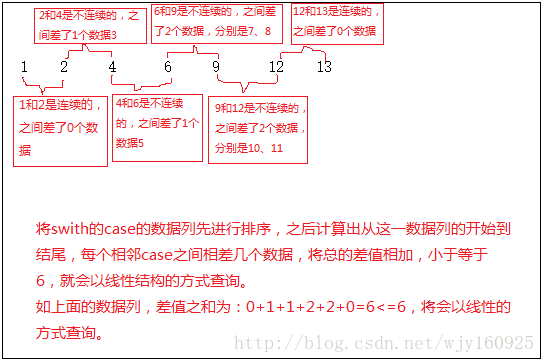
- 树形查找
当最大case值和最小case值之差大于255的情况下,此时,编译器会采用树形查找。即,将数据由小到大排列,并取中间值(如果是偶数,就取中间两个靠右的那一个),在左右两边继续取中间值划分(左右两边划分不需要将中间值算进去),直到小于等于3个数据的时候不在划分。
内存泄露
https://blog.csdn.net/u012662731/article/details/78652651
const
作用
- 修饰变量,说明该变量不可以被改变;
- 修饰指针,分为指向常量的指针和指针常量;
- 常量引用,经常用于形参类型,即避免了拷贝,又避免了函数对值的修改;
- 修饰成员函数,说明该成员函数内不能修改成员变量。
使用
const 使用
1 | // 类 |
static
- 修饰普通变量,修改变量的存储区域和生命周期,使变量存储在静态区,在 main 函数运行前就分配了空间,如果有初始值就用初始值初始化它,如果没有初始值系统用默认值初始化它。
- 修饰普通函数,表明函数的作用范围,仅在定义该函数的文件内才能使用。在多人开发项目时,为了防止与他人命名空间里的函数重名,可以将函数定位为 static。
- 修饰成员变量,修饰成员变量使所有的对象只保存一个该变量,而且不需要生成对象就可以访问该成员。
- 修饰成员函数,修饰成员函数使得不需要生成对象就可以访问该函数,但是在 static 函数内不能访问非静态成员。
this 指针
this指针是一个隐含于每一个非静态成员函数中的特殊指针。它指向调用该成员函数的那个对象。- 当对一个对象调用成员函数时,编译程序先将对象的地址赋给
this指针,然后调用成员函数,每次成员函数存取数据成员时,都隐式使用this指针。 - 当一个成员函数被调用时,自动向它传递一个隐含的参数,该参数是一个指向这个成员函数所在的对象的指针。
this指针被隐含地声明为:ClassName *const this,这意味着不能给this指针赋值;在ClassName类的const成员函数中,this指针的类型为:const ClassName* const,这说明不能对this指针所指向的这种对象是不可修改的(即不能对这种对象的数据成员进行赋值操作);this并不是一个常规变量,而是个右值,所以不能取得this的地址(不能&this)。- 在以下场景中,经常需要显式引用
this指针:- 为实现对象的链式引用;
- 为避免对同一对象进行赋值操作;
- 在实现一些数据结构时,如
list。
inline 内联函数
特征
- 相当于把内联函数里面的内容写在调用内联函数处;
- 相当于不用执行进入函数的步骤,直接执行函数体;
- 相当于宏,却比宏多了类型检查,真正具有函数特性;
- 编译器一般不内联包含循环、递归、switch 等复杂操作的内联函数;
- 在类声明中定义的函数,除了虚函数的其他函数都会自动隐式地当成内联函数。
使用
inline 使用
1 | // 声明1(加 inline,建议使用) |
编译器对 inline 函数的处理步骤
- 将 inline 函数体复制到 inline 函数调用点处;
- 为所用 inline 函数中的局部变量分配内存空间;
- 将 inline 函数的的输入参数和返回值映射到调用方法的局部变量空间中;
- 如果 inline 函数有多个返回点,将其转变为 inline 函数代码块末尾的分支(使用 GOTO)。
优缺点
优点
- 内联函数同宏函数一样将在被调用处进行代码展开,省去了参数压栈、栈帧开辟与回收,结果返回等,从而提高程序运行速度。
- 内联函数相比宏函数来说,在代码展开时,会做安全检查或自动类型转换(同普通函数),而宏定义则不会。
- 在类中声明同时定义的成员函数,自动转化为内联函数,因此内联函数可以访问类的成员变量,宏定义则不能。
- 内联函数在运行时可调试,而宏定义不可以。
缺点
- 代码膨胀。内联是以代码膨胀(复制)为代价,消除函数调用带来的开销。如果执行函数体内代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。
- inline 函数无法随着函数库升级而升级。inline函数的改变需要重新编译,不像 non-inline 可以直接链接。
- 是否内联,程序员不可控。内联函数只是对编译器的建议,是否对函数内联,决定权在于编译器。
虚函数(virtual)可以是内联函数(inline)吗?
Are “inline virtual” member functions ever actually “inlined”?
- 虚函数可以是内联函数,内联是可以修饰虚函数的,但是当虚函数表现多态性的时候不能内联。
- 内联是在编译器建议编译器内联,而虚函数的多态性在运行期,编译器无法知道运行期调用哪个代码,因此虚函数表现为多态性时(运行期)不可以内联。
inline virtual唯一可以内联的时候是:编译器知道所调用的对象是哪个类(如Base::who()),这只有在编译器具有实际对象而不是对象的指针或引用时才会发生。
虚函数内联使用
1 | #include <iostream> |
volatile
volatile int i = 10;
- volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素(操作系统、硬件、其它线程等)更改。所以使用 volatile 告诉编译器不应对这样的对象进行优化。
- volatile 关键字声明的变量,每次访问时都必须从内存中取出值(没有被 volatile 修饰的变量,可能由于编译器的优化,从 CPU 寄存器中取值)
- const 可以是 volatile (如只读的状态寄存器)
- 指针可以是 volatile
assert()
断言,是宏,而非函数。assert 宏的原型定义在 <assert.h>(C)、<cassert>(C++)中,其作用是如果它的条件返回错误,则终止程序执行。可以通过定义 NDEBUG 来关闭 assert,但是需要在源代码的开头,include <assert.h> 之前。
assert() 使用
1 | #define NDEBUG // 加上这行,则 assert 不可用 |
sizeof()
- sizeof 对数组,得到整个数组所占空间大小。
- sizeof 对指针,得到指针本身所占空间大小。
union 联合
联合(union)是一种节省空间的特殊的类,一个 union 可以有多个数据成员,但是在任意时刻只有一个数据成员可以有值。当某个成员被赋值后其他成员变为未定义状态。联合有如下特点:
- 默认访问控制符为 public
- 可以含有构造函数、析构函数
- 不能含有引用类型的成员
- 不能继承自其他类,不能作为基类
- 不能含有虚函数
- 匿名 union 在定义所在作用域可直接访问 union 成员
- 匿名 union 不能包含 protected 成员或 private 成员
- 全局匿名联合必须是静态(static)的
union 使用
1 | #include<iostream> |
friend 友元类和友元函数
- 能访问私有成员
- 破坏封装性
- 友元关系不可传递
- 友元关系的单向性
- 友元声明的形式及数量不受限制
虚函数问题
虚函数、纯虚函数
- 类里如果声明了虚函数,这个函数是实现的,哪怕是空实现,它的作用就是为了能让这个函数在它的子类里面可以被覆盖,这样的话,编译器就可以使用后期绑定来达到多态了。纯虚函数只是一个接口,是个函数的声明而已,它要留到子类里去实现。
- 虚函数在子类里面也可以不重载的;但纯虚函数必须在子类去实现。
- 虚函数的类用于 “实作继承”,继承接口的同时也继承了父类的实现。当然大家也可以完成自己的实现。纯虚函数关注的是接口的统一性,实现由子类完成。
- 带纯虚函数的类叫抽象类,这种类不能直接生成对象,而只有被继承,并重写其虚函数后,才能使用。抽象类被继承后,子类可以继续是抽象类,也可以是普通类。
- 虚基类是虚继承中的基类,具体见下文虚继承。
虚函数指针、虚函数表
- 虚函数指针:在含有虚函数类的对象中,指向虚函数表,在运行时确定。
- 虚函数表:在程序只读数据段(
.rodata section,见:目标文件存储结构),存放虚函数指针,如果派生类实现了基类的某个虚函数,则在虚表中覆盖原本基类的那个虚函数指针,在编译时根据类的声明创建。
虚继承
虚继承用于解决多继承条件下的菱形继承问题(浪费存储空间、存在二义性)。
底层实现原理与编译器相关,一般通过虚基类指针和虚基类表实现,每个虚继承的子类都有一个虚基类指针(占用一个指针的存储空间,4字节)和虚基类表(不占用类对象的存储空间)(需要强调的是,虚基类依旧会在子类里面存在拷贝,只是仅仅最多存在一份而已,并不是不在子类里面了);当虚继承的子类被当做父类继承时,虚基类指针也会被继承。
实际上,vbptr 指的是虚基类表指针(virtual base table pointer),该指针指向了一个虚基类表(virtual table),虚表中记录了虚基类与本类的偏移地址;通过偏移地址,这样就找到了虚基类成员,而虚继承也不用像普通多继承那样维持着公共基类(虚基类)的两份同样的拷贝,节省了存储空间。
虚继承、虚函数
- 相同之处:都利用了虚指针(均占用类的存储空间)和虚表(均不占用类的存储空间)
- 不同之处:
- 虚继承
- 虚基类依旧存在继承类中,只占用存储空间
- 虚基类表存储的是虚基类相对直接继承类的偏移
- 虚函数
- 虚函数不占用存储空间
- 虚函数表存储的是虚函数地址
- 虚继承
内存分配和管理
malloc、calloc、realloc、alloca
- malloc:申请指定字节数的内存。申请到的内存中的初始值不确定。
- calloc:为指定长度的对象,分配能容纳其指定个数的内存。申请到的内存的每一位(bit)都初始化为 0。
- realloc:更改以前分配的内存长度(增加或减少)。当增加长度时,可能需将以前分配区的内容移到另一个足够大的区域,而新增区域内的初始值则不确定。
- alloca:在栈上申请内存。程序在出栈的时候,会自动释放内存。但是需要注意的是,alloca 不具可移植性, 而且在没有传统堆栈的机器上很难实现。alloca 不宜使用在必须广泛移植的程序中。C99 中支持变长数组 (VLA),可以用来替代 alloca。
malloc、free
用于分配、释放内存
malloc、free 使用
申请内存,确认是否申请成功
1 | char *str = (char*) malloc(100); |
释放内存后指针置空
1 | free(p); |
new、delete
- new / new[]:完成两件事,先底层调用 malloc 分配了内存,然后调用构造函数(创建对象)。
- delete/delete[]:也完成两件事,先调用析构函数(清理资源),然后底层调用 free 释放空间。
- new 在申请内存时会自动计算所需字节数,而 malloc 则需我们自己输入申请内存空间的字节数。
new、delete 使用
申请内存,确认是否申请成功
1 | int main() |
定位 new
定位 new(placement new)允许我们向 new 传递额外的地址参数,从而在预先指定的内存区域创建对象。
1 | new (place_address) type |
place_address是个指针initializers提供一个(可能为空的)以逗号分隔的初始值列表
delete this 合法吗?
Is it legal (and moral) for a member function to say delete this?
合法,但:
- 必须保证 this 对象是通过
new(不是new[]、不是 placement new、不是栈上、不是全局、不是其他对象成员)分配的 - 必须保证调用
delete this的成员函数是最后一个调用 this 的成员函数 - 必须保证成员函数的
delete this后面没有调用 this 了 - 必须保证
delete this后没有人使用了