MapReduce局限性
MapReduce的局限性:
1)代码繁琐;
2)只能够支持map和reduce方法;
3)执行效率低下;
4)不适合迭代多次、交互式、流式的处理;
框架多样化:
1)批处理(离线):MapReduce、Hive、Pig
2)流式处理(实时): Storm、JStorm
3)交互式计算:Impala
Hive,Hbase,HDFS等之间的关系
Hive:
Hive不支持更改数据的操作,Hive基于数据仓库,提供静态数据的动态查询。其使用类SQL语言,底层经过编译转为MapReduce程序,在Hadoop上运行,数据存储在HDFS上。
HDFS:
HDFS是GFS的一种实现,他的完整名字是分布式文件系统,类似于FAT32,NTFS,是一种文件格式,是底层的。
Hive与Hbase的数据一般都存储在HDFS上。Hadoop HDFS为他们提供了高可靠性的底层存储支持。
Hbase:
Hbase是Hadoop database,即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据。
Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS(关系型数据库)数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
Pig:
Pig的语言层包括一个叫做PigLatin的文本语言,Pig Latin是面向数据流的编程方式。Pig和Hive类似更侧重于数据的查询和分析,底层都是转化成MapReduce程序运行。
区别是Hive是类SQL的查询语言,要求数据存储于表中,而Pig是面向数据流的一个程序语言。
Spark多种运行模式
测试或实验性质的本地运行模式(单机)
- 该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,通常用来验证开发出来的应用程序逻辑上有没有问题。其中N代表可以使用N个线程,每个线程拥有一个core。如果不指定N,则默认是1个线程(该线程有1个core)。
指令示例:
1)spark-shell –master local 效果是一样的
2)spark-shell –master local[4] 代表会有4个线程(每个线程一个core)来并发执行应用程序。运行该模式非常简单,只需要把Spark的安装包解压后,改一些常用的配置即可使用,而不用启动Spark的Master、Worker守护进程( 只有集群的Standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非你要用到HDFS),这是和其他模式的区别,要记住才能理解。
测试或实现性质的本地伪集群运行模式(单机模拟集群)
这种运行模式,和Local[N]很像,不同的是,它会在单机启动多个进程来模拟集群下的分布式场景,而不像Local[N]这种多个线程只能在一个进程下委屈求全的共享资源。通常也是用来验证开发出来的应用程序逻辑上有没有问题,或者想使用Spark的计算框架而没有太多资源。
指令示例:
1)spark-shell –master local-cluster[2, 3, 1024]
用法是:提交应用程序时使用local-cluster[x,y,z]参数:x代表要生成的executor数,y和z分别代表每个executor所拥有的core和memory数。
该模式依然非常简单,只需要把Spark的安装包解压后,改一些常用的配置即可使用。而不用启动Spark的Master、Worker守护进程( 只有集群的standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非你要用到HDFS),这是和其他模式的区别哦,要记住才能理解。
spark自带Cluster Manager的standalone Client模式(集群)
需要在多台机器上同时部署spark环境
- 和单机运行的模式不同,这里必须在执行应用程序前,先启动Spark的Master和Worker守护进程。不用启动Hadoop服务,除非你用到了HDFS的内容。可以在想要做为Master的节点上用start-all.sh一条命令即可,这种运行模式,可以使用Spark的8080 web ui来观察资源和应用程序的执行情况了。用如下命令提交应用程序
指令示例:
1)spark-shell –master spark://wl1:7077
或者
2)spark-shell –master spark://wl1:7077 –deploy-mode client产生的进程:
①Master进程做为cluster manager,用来对应用程序申请的资源进行管理
②SparkSubmit 做为Client端和运行driver程序
③CoarseGrainedExecutorBackend 用来并发执行应用程序
spark 自带Cluster manager 的Standalone cluster模式(集群)
- 这种运行模式和上面第3个还是有很大的区别的。使用如下命令执行应用程序
- 指令示例:
spark-submit --master spark://wl1:6066 --deploy-mode cluster
第4种模式和第3种模型的区别:
①客户端的SparkSubmit进程会在应用程序提交给集群之后就退出
②Master会在集群中选择一个Worker进程生成一个子进程DriverWrapper来启动driver程序
③而该DriverWrapper 进程会占用Worker进程的一个core,所以同样的资源下配置下,会比第3种运行模式,少用1个core来参与计算
④应用程序的结果,会在执行driver程序的节点的stdout中输出,而不是打印在屏幕上
基于YARN的Resource Manager 的Client 模式(集群)
现在越来越多的场景,都是Spark跑在Hadoop集群中,所以为了做到资源能够均衡调度,会使用YARN来做为Spark的Cluster Manager,来为Spark的应用程序分配资源。在执行Spark应用程序前,要启动Hadoop的各种服务。由于已经有了资源管理器,所以不需要启动Spark的Master、Worker守护进程。
使用如下命令执行应用程序:
指令示例:
1)spark-shell –master yarn
或者
2)spark-shell –master yarn –deploy-mode client
- 提交应用程序后,各节点会启动相关的JVM进程,如下:
- 在Resource Manager节点上提交应用程序,会生成SparkSubmit进程,该进程会执行driver程序。
- RM会在集群中的某个NodeManager上,启动一个ExecutorLauncher进程,来做为ApplicationMaster。
- 另外,RM也会在多个NodeManager上生成CoarseGrainedExecutorBackend进程来并发的执行应用程序。
基于YARN的Resource Manager 的 Cluster 模式(集群)
- 指令示例:
spark-shell --master yarn --deploy-mode cluster
和第5种运行模式,区别如下:
- ①在Resource Manager端提交应用程序,会生成SparkSubmit进程,该进程只用来做Client端,应用程序提交给集群后,就会删除该进程。
- ②Resource Manager在集群中的某个NodeManager上运行ApplicationMaster,该AM同时会执行driver程序。紧接着,会在各NodeManager上运行CoarseGrainedExecutorBackend来并发执行应用程序。
- ③应用程序的结果,会在执行driver程序的节点的stdout中输出,而不是打印在屏幕上。
此外,还有**Spark On Mesos**模式 可以参阅:
http://ifeve.com/spark-mesos-spark/
spark中cache和persist的区别
cache和persist都是用于将一个RDD进行缓存的,这样在之后使用的过程中就不需要重新计算了,可以大大节省程序运行时间。cache()调用了persist(),cache只有一个默认的缓存级别MEMORY_ONLY ,而persist可以根据情况设置其它的缓存级别。
1 | object StorageLevel { |
useDisk:使用硬盘(外存)
useMemory:使用内存
useOffHeap:使用堆外内存,这是Java虚拟机里面的概念,堆外内存意味着把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。
deserialized:反序列化,其逆过程序列化(Serialization)是java提供的一种机制,将对象表示成一连串的字节;而反序列化就表示将字节恢复为对象的过程。序列化是对象永久化的一种机制,可以将对象及其属性保存起来,并能在反序列化后直接恢复这个对象
replication:备份数(在多个节点上备份)
使用1
2
3xxDF.cache()
使用
xxDF.unpersist(true)
Spark SQL
起源
Hive: 类似于sql的Hive QL语言, sql==>mapreduce
- 特点:mapreduce
- 改进:hive on tez、hive on spark、hive on mapreduce
Spark: hive on spark ==> shark(hive on spark)
- shark推出:欢迎, 基于spark、基于内存的列式存储、与hive能够兼容
- 缺点:hive ql的解析、逻辑执行计划生成、执行计划的优化是依赖于hive的
仅仅只是把物理执行计划从mr作业替换成spark作业
Shark终止以后,产生了2个分支:
1)hive on spark
Hive社区,源码是在Hive中
2)Spark SQL
Spark社区,源码是在Spark中
支持多种数据源,多种优化技术,扩展性好很多
SQL on Hadoop
Hive
sql ==> mapreduce
metastore : 元数据
sql:database、table、view
facebookimpala
cloudera : cdh(建议大家在生产上使用的hadoop系列版本)、cm
sql:自己的守护进程执行的,非mr
metastorepresto
facebook
京东
sqldrill
sql
访问:hdfs、rdbms、json、hbase、mongodb、s3、hiveSpark SQL
sql
dataframe/dataset api
metastore
访问:hdfs、rdbms、json、hbase、mongodb、s3、hive ==> 外部数据源
Spark SQL is Apache Spark’s module for working with structured data.
有见到SQL字样吗?
Spark SQL它不仅仅有访问或者操作SQL的功能,还提供了其他的非常丰富的操作:外部数据源、优化
Spark SQL概述小结:
- Spark SQL的应用并不局限于SQL;
- 访问hive、json、parquet等文件的数据;
- SQL只是Spark SQL的一个功能而已;
===> Spark SQL这个名字起的并不恰当 - Spark SQL提供了SQL的api、DataFrame和Dataset的API;
使用场景
即席查询
将分析结果传到streaming
etl 清洗数据
把外部数据源的数据弄成dataFrame
大规模集群的查询
特点
A、容易集成
SparkSQL将SQL查询与Spark程序无缝对接,它允许用户使用SQL或熟悉的DataFrame API查询Spark程序内的结构化数据,可应用于Java、Scala、Python和R。
B、统一的数据访问方式
可使用同样的方式连接任何数据源,DataFrame和SQL提供了访问各种数据源的常用方式,包括Hive、Avro、Parquet、ORC、JSON和JDBC,甚至可以通过这些数据源直接加载数据。
C、Hive集成
能够在现有数据仓库上运行SQL或HiveSQL查询,SparkSQL支持HiveQL语法以及HiveSerDes(序列化和反序列化工具)和UDF(用户自定义函数),允许用户访问现有的Hive仓库。
D、标准的数据连接
通过JDBC或ODBC进行数据库连接,服务器模式为商业智能工具提供行业标准的JDBC和ODBC数据连接。
使用
SQL
Spark SQL的一种用法是直接执行SQL查询语句,你可使用最基本的SQL语法,也可以选择HiveQL语法。Spark SQL可以从已有的Hive中读取数据。更详细的请参考Hive Tables 这一节。如果用其他编程语言运行SQL,Spark SQL将以DataFrame返回结果。你还可以通过命令行command-line 或者 JDBC/ODBC 使用Spark SQL。
DataFrames
DataFrame是一种分布式数据集合,每一条数据都由几个命名字段组成。概念上来说,她和关系型数据库的表 或者 R和Python中的data frame等价,只不过在底层,DataFrame采用了更多优化。DataFrame可以从很多数据源(sources)加载数据并构造得到,如:结构化数据文件,Hive中的表,外部数据库,或者已有的RDD。
DataFrame API支持Scala, Java, Python, and R。
Datasets
Dataset是Spark-1.6新增的一种API,目前还是实验性的。Dataset想要把RDD的优势(强类型,可以使用lambda表达式函数)和Spark SQL的优化执行引擎的优势结合到一起。Dataset可以由JVM对象构建(constructed )得到,而后Dataset上可以使用各种transformation算子(map,flatMap,filter 等)。
Dataset API 对 Scala 和 Java的支持接口是一致的,但目前还不支持Python,不过Python自身就有语言动态特性优势(例如,你可以使用字段名来访问数据,row.columnName)。对Python的完整支持在未来的版本会增加进来。
加载数据
可以加载为RDD、DataFrame、DataSet
可以从本地、云端(HDFS,S3)
1 | 将数据加载成RDD |
RDD和DataFrame关联
1 | import org.apache.spark.sql.Row |
如果格式是Json/Parquet等智能一点的,spark会自动推测出来,不用手动指定schema
1 | val usersDF = spark.read.format("parquet").load("file:///home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet") |
从Cloud读取数据: HDFS/S31
2
3
4
5
6
val hdfsRDD = sc.textFile("hdfs://path/file")
val s3RDD = sc.textFile("s3a://bucket/object")
spark.read.format("text").load("hdfs://path/file")
spark.read.format("text").load("s3a://bucket/object")
DataFrame和SQL的功能对比
DataFrame = RDD + Schema
(定义case class,然后用反射的方式自动生成schema)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._
// Define the schema using a case class.
// Note: Case classes in Scala 2.10 can support only up to 22 fields. To work around this limit,
// you can use custom classes that implement the Product interface.
case class Person(name: String, age: Int)
// Create an RDD of Person objects and register it as a table.
val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()
people.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.
val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
// The results of SQL queries are DataFrames and support all the normal RDD operations.
// The columns of a row in the result can be accessed by field index:
teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
// or by field name:
teenagers.map(t => "Name: " + t.getAs[String]("name")).collect().foreach(println)
// row.getValuesMap[T] retrieves multiple columns at once into a Map[String, T]
teenagers.map(_.getValuesMap[Any](List("name", "age"))).collect().foreach(println)
// Map("name" -> "Justin", "age" -> 19)
DataFrame catalyst优化
DataFrame可以处理text,json,parquet等
SQL和API在DF里,都经过了catalyst优化,(不管菜鸡把SQL写成什么样,最后执行效率都一样)
savemode
1 | val df=spark.read.format("json").load("file:///home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json") |
Spark架构
Apache Spark是继Hadoop之后的新一代大数据分布式计算框架,它与Hadoop MapReduce的不同之处在于Spark Job的中间结果可以保存在内存中,不再需要读写HDFS,因此它能更好地适用于机器学习、数据挖掘等需要迭代的算法。Spark最初的设计目标是可以更加高效低分析数据,不仅要使分析程序运行速度快,也要能高效地编写程序。为此Spark使用Scala语言编写,Scala语言集成了面向对象编程和函数式编程的各种特性。基于Scala,Spark为用户提供了交互式的编程方式。
Spark中的基本概念:
- RDD:Resilient Distributed Dataset(弹性分布式数据集)是一个分布式对象集合,每个RDD可以分成多个分区(一个数据集片段),并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
- Transformation:RDD的一种操作方式,用于指定RDD之间的相互依赖关系。
- Action:RDD的一种操作方式,用于执行计算并指定输出形式。
- DAG:Directed Acyclic Graph(有向无环图),反映RDD之间的依赖关系。
- Executor:运行在Worker Node(工作节点)上的一个进程,为应用程序存储数据。
- 任务:Task,运行在Executor上的工作单元。
- 作业:Job,一个作业包含多个RDD及作用于相应RDD上的各种操作,一个action对应一个job。
- 阶段:Stage,调度作业的基本单位,一个作业分为多组任务,每组任务被称为“阶段”或 “任务集”。xxxbykey会把一个stage分成两个。
- Application:1 driver + n executors
- Driver program:运行main的程序
- Deploy mode:driver进程运行在哪里。cluster、client
运行流程
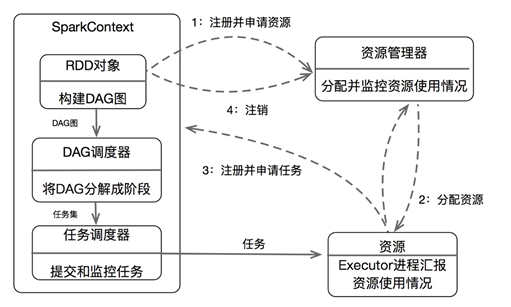
在Spark中,一个Application由一个任务控制节点(Driver)和若干个作业构成,一个作业由多个阶段构成,一个阶段由多个任务组成。如图2.4所示Spark的基本运行流程如下:
(1)当一个Spark应用被提交时,首先需要为这个应用建立基本运行环境,即由任务控制节点创建一个SparkContext,由SparkContext负责和资源管理器通信以及申请运行Executor的资源、分配任务、监控等。
(2)资源管理器为Executor分配资源并启动Executor进程,其运行情况将随着“心跳”发送到资源管理器上。
(3)SparkContext根据弹性数据集的依赖关系构建DAG图,DAG调度器将解析DAG图,把其分解成多个“阶段”,并计算出各个阶段之间的依赖关系,然后把每个“任务集”提交给底层的任务调度器(Task Scheduler)进行处理。
(4)Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,任务执行结果将反馈给任务调度器,随后传递给DAG调度器,程序运行完毕后写入数据库并释放资源。
RDD结构
RDD是一个抽象类
带泛型的,可以支持多种类型:String,Person,User
(1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
def compute()
(2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。def getPartitions()
(3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
def getDependencies()
(4)(可选)一个Partitioner,即RDD的分片函数,分区策略。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
def getPreferredLocations()
(5)(可选)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,数据在哪优先把作业调度到数据所在的节点进行计算。
val partitioner:Option[Partitioner] = None
RDD的特点
- 是一个分区的只读记录的集合;
- 一个具有容错机制的特殊集;
- 只能通过在稳定的存储器或其他RDD上的确定性操作(转换)来创建;
- 可以分布在集群的节点上,以函数式操作集合的方式,进行各种并行操作
RDD之所以为“弹性”的特点
- 基于Lineage的高效容错(第n个节点出错,会从第n-1个节点恢复,血统容错);
- Task如果失败会自动进行特定次数的重试(默认4次);
- Stage如果失败会自动进行特定次数的重试(可以值运行计算失败的阶段),只计算失败的数据分片;
- 数据调度弹性:DAG TASK 和资源管理无关;
- checkpoint;
- 自动的进行内存和磁盘数据存储的切换;
窄依赖和宽依赖
- 窄依赖(pipeline-able):一个父RDD的partition至多被子RDD的某个partition使用一次。
- 宽依赖(shuffle):会被子RDD的partition使用多次。
首先,从计算过程来看,窄依赖是数据以管道方式经一系列计算操作可以运行在了一个集群节点上,如(map、filter等),宽依赖则可能需要将数据通过跨节点传递后运行(如groupByKey),有点类似于MR的shuffle过程。
shuffle会分成两个stage。
其次,从失败恢复来看,窄依赖的失败恢复起来更高效,因为它只需找到父RDD的一个对应分区即可,而且可以在不同节点上并行计算做恢复;宽依赖则牵涉到父RDD的多个分区,恢复起来相对复杂些。
创建RDD的三种方式
在RDD中,通常就代表和包含了Spark应用程序的输入源数据。
当我们,在创建了初始的RDD之后,才可以通过Spark Core提供的transformation算子,对该RDD进行transformation(转换)操作,来获取其他的RDD。
Spark Core为我们提供了三种创建RDD的方式,包括:
- 使用程序中的集合创建RDD
- 使用本地文件创建RDD
- 使用HDFS文件创建RDD
应用场景
- 使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造测试数据,来测试后面的spark应用的流程
- 使用本地文件创建RDD,主要用于的场景为:在本地临时性地处理一些存储了大量数据的文件
- 使用HDFS文件创建RDD,应该是最常用的生产环境处理方式,主要可以针对HDFS上存储的大数据,进行离线批处理操作
并行化创建RDD
如果要通过并行化集合来创建RDD,需要针对程序中的集合,调用SparkContext中的parallelize()方法。Spark会将集合中的数据拷贝到集群上去,形成一个分布式的数据集合,也就是一个RDD。即:集合中的部分数据会到一个节点上,而另一部分数据会到其它节点上。然后就可以采用并行的方式来操作这个分布式数据集合。
在调用parallelize()方法时,有一个重要的参数可以指定,就是要将集合切分成多少个partition。Spark会为每一个partition运行一个task来进行处理。Spark官方的建议是,为集群中的每个CPU创建2-4个partition。Spark默认会根据集群的情况来设置partition的数量。但是也可以在调用parallelize()方法时,传入第二个参数,来设置RDD的partition数量。比如,parallelize(arr, 10)
1 | // 并行化创建RDD部分代码 |
使用textFile方法,通过本地文件或HDFS创建RDD
Spark是支持使用任何Hadoop支持的存储系统上的文件创建RDD的,比如说HDFS、Cassandra、HBase以及本地文件。通过调用SparkContext的textFile()方法,可以针对本地文件或HDFS文件创建RDD。
一些特例的方法来创建RDD
- SparkContext的wholeTextFiles()方法,可以针对一个目录中的大量小文件,返回由(fileName,fileContent)组成的pair,即pairRDD,而不是普通的RDD。该方法返回的是文件名字和文件中的具体内容;而普通的textFile()方法返回的RDD中,每个元素就是文本中一行文本。
- SparkContext的sequenceFileK,V方法,可以针对SequenceFile创建RDD,K和V泛型类型就是SequenceFile的key和value的类型。K和V要求必须是Hadoop的序列化机制,比如IntWritable、Text等。
- SparkContext的hadoopRDD()方法,对于Hadoop的自定义输入类型,可以创建RDD。该方法接收JobConf、InputFormatClass、Key和Value的Class。
- SparkContext的objectFile()方法,可以针对之前调用的RDD的saveAsObjectFile()创建的对象序列化的文件,反序列化文件中的数据,并创建一个RDD。
spark context
连接到Spark“集群”, 通过sparkcontext来创建RDD、广播变量到集群
在创建sparkcontext之前需要创建一个sparkconf对象,
Spark Streaming
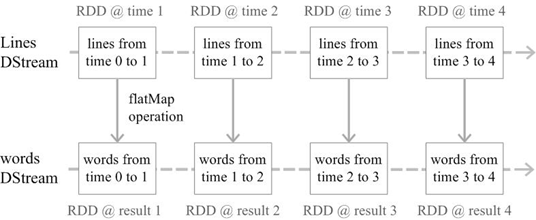
Spark Streaming是Spark的核心组件之一,它可结合批处理和交互查询,提高了Spark处理大规模流式数据的能力,适合一些需要对历史数据和实时数据结合分析的应用场景。Spark Streaming可使用多种输入数据源,如Apache HDFS、Apache Kafka、Apache Flume,甚至包括Socket套接字。经处理后的数据可以存储至数据库、文件系统或者显式地输出。Spark Streaming的基本原理是把实时输入数据流以秒级时间片为单位进行拆分,然后以类似批处理的方式利用Spark引擎处理每个时间片数据,执行流程如图

Spark Streaming主要的抽象是DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)分成一段段的DStream,每一段数据转换为Spark中的RDD,对DStream的操作都最终转变为对相应的RDD的操作。图2.6展示了当进行单词统计时,每个时间片的数据(存储句子的RDD)经过flatMap操作,生成了存储单词的RDD。
1 | package com.imooc.spark |
YARN架构
1 RM(ResourceManager) + N NM(NodeManager)
ResourceManager的职责: 一个集群active状态的RM只有一个,负责整个集群的资源管理和调度
- 1)处理客户端的请求(启动/杀死)
- 2)启动/监控ApplicationMaster(一个作业对应一个AM)
- 3)监控NM
- 4)系统的资源分配和调度
NodeManager:整个集群中有N个,负责单个节点的资源管理和使用以及task的运行情况
- 1)定期向RM汇报本节点的资源使用请求和各个Container的运行状态
- 2)接收并处理RM的container启停的各种命令
- 3)单个节点的资源管理和任务管理
ApplicationMaster:每个应用/作业对应一个,负责应用程序的管理
- 1)数据切分
- 2)为应用程序向RM申请资源(container),并分配给内部任务
- 3)与NM通信以启停task, task是运行在container中的
- 4)task的监控和容错
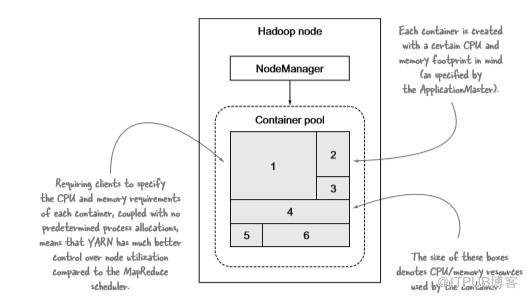
Container:
对任务运行情况的描述:cpu、memory、环境变量
YARN执行流程
- 1)用户向YARN提交作业
- 2)RM为该作业分配第一个container(AM)
- 3)RM会与对应的NM通信,要求NM在这个container上启动应用程序的AM
- 4) AM首先向RM注册,然后AM将为各个任务申请资源,并监控运行情况
- 5)AM采用轮训的方式通过RPC协议向RM申请和领取资源
- 6)AM申请到资源以后,便和相应的NM通信,要求NM启动任务
- 7)NM启动我们作业对应的task
YARN环境搭建1
2
3
4
5
6
7
8
9
10
11
12
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
启动yarn:sbin/start-yarn.sh
验证是否启动成功jpsResourceManagerNodeManager
停止yarn: sbin/stop-yarn.sh
提交mr作业到yarn上运行: wc
/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar
hadoop jar /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /input/wc/hello.txt /output/wc/
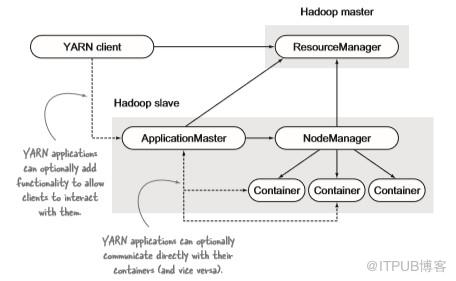
Yarn应用程序涉及三大组件 - 客户端,ApplicationMaster(AM)和容器,如图2.3所示。启动新的Yarn应用程序需从Yarn客户端开始,该客户端与ResourceManager通信以创建新的Yarn ApplicationMaster实例,此过程Yarn客户端会让ResourceManager通知ApplicationMaster物理资源要求。
ApplicationMaster是Yarn应用程序主进程,不执行任何特定于应用程序的工作,因为这些函数被委托给容器。但是,它负责管理特定于应用程序的容器:询问ResourceManager其创建容器的意图,然后与NodeManager联系以实际执行容器创建。作为此过程的一部分,ApplicationMaster必须根据主机启动容器,并确定容器的内存和CPU要求以指定容器所需资源。
ResourceManager根据资源要求安排工作,它使主机能够运行混合容器,如图2.4所示。ApplicationMaster负责应用程序的特定容错,在容器失败时从ResourceManager接收状态消息,并基于具体事件采取操作(通过要求ResourceManager创建新容器解决)或忽略这些事件。
Flume
- Flume是一个分布式的、可靠的、高可用的海量日志采集、聚合和传输的系统
- 数据流模型:Source-Channel-Sink
- 事务机制保证消息传递的可靠性
- 内置丰富插件,轻松与其他系统集成
- Java实现,优秀的系统框架设计,模块分明,易于开发
Flume基本组件
- Event:消息的基本单位,有header和body组成
Agent:JVM进程,负责将一端外部来源产生的消息转 发到另一端外部的目的地
- Source: 从数据发生器接收数据,并将接收的数据以Flume的event格式传递给一个或者多个通道channal,Flume提供多种数据接收的方式,比如Avro,Thrift,twitter1%,log4j等
- Channel: channal是一种短暂的存储容器,它将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,它在source和sink间起着一共桥梁的作用,channal是一个完整的事务,这一点保证了数据在收发的时候的一致性. 并且它可以和任意数量的source和sink链接. 支持的类型有: JDBC channel , File System channel , Memort channel等.
- Sink:sink将数据存储到集中存储器比如Hbase和HDFS,它从channals消费数据(events)并将其传递给目标地. 目标地可能是另一个source,也可能HDFS,HBase
Flume插件:
- Interceptors拦截器: 用于source和channel之间,用来更改或者检查Flume的events数据
- 管道选择器 channels Selectors: 在多管道是被用来选择使用那一条管道来传递数据(events). 管道选择器又分为如下两种:
- 默认管道选择器: 每一个管道传递的都是相同的events
- 多路复用通道选择器: 依据每一个event的头部header的地址选择管道.
- sink线程:用于激活被选择的sinks群中特定的sink,用于负载均衡.
flume典型的使用场景
多代理流

从第一台机器的flume agent传送到第二台机器的flume agent。
例:
规划:
hadoop02:tail-avro.properties
使用 exec “tail -F /home/hadoop/testlog/welog.log”获取采集数据
使用 avro sink 数据都下一个 agent
hadoop03:avro-hdfs.properties
使用 avro 接收采集数据
使用 hdfs sink 数据到目的地
1 | #tail-avro.properties |
1 | #avro-hdfs.properties |
多路复用采集

在一份agent中有多个channel和多个sink,然后多个sink输出到不同的文件或者文件系统中。
规划:
Hadoop02:(tail-hdfsandlogger.properties)
使用 exec “tail -F /home/hadoop/testlog/datalog.log”获取采集数据
使用 sink1 将数据 存储hdfs
使用 sink2 将数据都存储 控制台
1 |
|
Kafka
基本概念
- kafka作为集群运行在一个或者多个服务器上
- kafka集群存储的消息是以topic为类别记录的
- kafka存储的消息是k-v键值对,k是offset偏移量,v就是消息的内容
- topic:kafka将消息分门别类,每一类的消息称之为topic
- broker:已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker). 消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
- 消息:kafka会保存消息直到它过期,无论是否被消费了。
- producer:发布消息的对象,往某个topic中发布消息,也负责选择发布到topic中的哪个分区
- consumer:订阅消息并处理发布的消息的对象
- patition:topic是逻辑上的概念,patition是物理概念。每个分区都是一个顺序的,不可变的消息队列,并且可以持续添加,producer生产的消息都会append到队列的末尾,而不是随机读写的。分区中的消息都会被分了一个序列号,这个序列号在分区内是唯一的,也就是分区内的偏移量。
- 如何消费:
kafka的生产者没有保持消息消费的顺序,消费的顺序是通过偏移量交给消费者的,消费者持有的元数据就是消息的offset,消费者通过控制offset的移动来决定读取哪里的消息。正常情况下,当消费者消费消息的时候,偏移量是线性增长的。如果消费者想要重新读取数据的时候,就需要将偏移量向前移动。 - 为什么说是分布式和冗余备份的:
分区被分布到集群中的各个服务器中,每个服务器处理它所拥有的分区。根据配置,每个分区还可以复制到其他服务器作为备份容错。每个分区拥有一个leader,有一个或者多个follower(冗余备份的)。一个broker可以是一个分区的leader,同时也可以是别的分区的follwer,避免了所有的请求只让一个或者几个服务器处理,负载均衡。
某个broker如果是一个分区的leader,那么它处理这个分区上的所有读写请求,而follower分区被动的复制数据。如果leader宕机,则follower就可以被推举为leader。 - 为什么说是持久性的:
kafka使用文件存储消息,并且会保存所有消息直到它过期,无论是否消费。 consumer和topic的关系
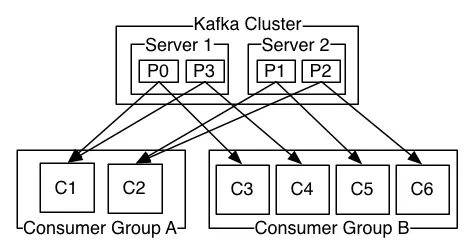
这个kafka集群中有两个broker,broker1下有partition0和partition3,broker2下有partition1和partition2。
有两个消费者集群,消费者集群A拥有两个消费者C1和C2,消费者集群B拥有四个消费者C3,C4,C5,C6。
每个partition只能被一个消费者集群中的一个消费者消费,比如broker1中partition0,只能被Consumer GroupA中的C1消费,只能被Consumer GroupB中的C3消费,kafak会确保这个消费者是这个partition的唯一消费者。
因为偏移量的唯一值是基于一个分区内的,producer生产的消息按照一定的算法分配到不同的分区,在各个分区内部,偏移量是线性增长的,所以在一个分区内消费消息是可以保持顺序的。但是如果topic里有多个partition的话,那么不能保证全局的消息是顺序的。
一个消费组中有多个消费者可以提高消费消息的并发性,并且当partition的消费者出现故障,那么这个partition可以分配给同组的其他消费者,从而提高他的容错性。
因为一个partition只能被一个同组的消费者消费,所以当同组中的消费者数量多于partition的数量时,注定有消费者无法消费partition。
每个消费者可以消费一个到多个partition。发布订阅
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。发布到topic的消息会被所有订阅者消费。消费端为拉模型,消费状态和订阅关系由客户端负责维护,消息消费完后不会立即删除,会保留历史消息。
应用场景
(1)作为消息队列。因为Kafka具有高吞吐量且拥有消息主题分区、备份、容错等特性,使得它适合使用在大规模、高强度的消息数据处理的系统中。
(2)作为流式计算数据源。Kafka消息数据的生产者为流数据产生系统,将数据流分发给Kafka topic,随后Storm、Spark Streaming等流数据计算系统可以实时消费并计算数据。
(3)作为系统用户行为数据源。此时系统将用户的行为例如访问网站、搜索记录、兴趣标签、网页停留时间等数据实时或者周期性的发布到Kafka topic,作为对接系统数据的来源。
(4)作为事件源。在基于事件驱动的系统中,事件可以设计成合理的格式,作为 Kafka 消息数据存储起来,以便相应系统模块做定期或实时处理。Kafka支持大数据量存储、具有备份和容错机制的特性可以让事件驱动型系统更加高效健壮。
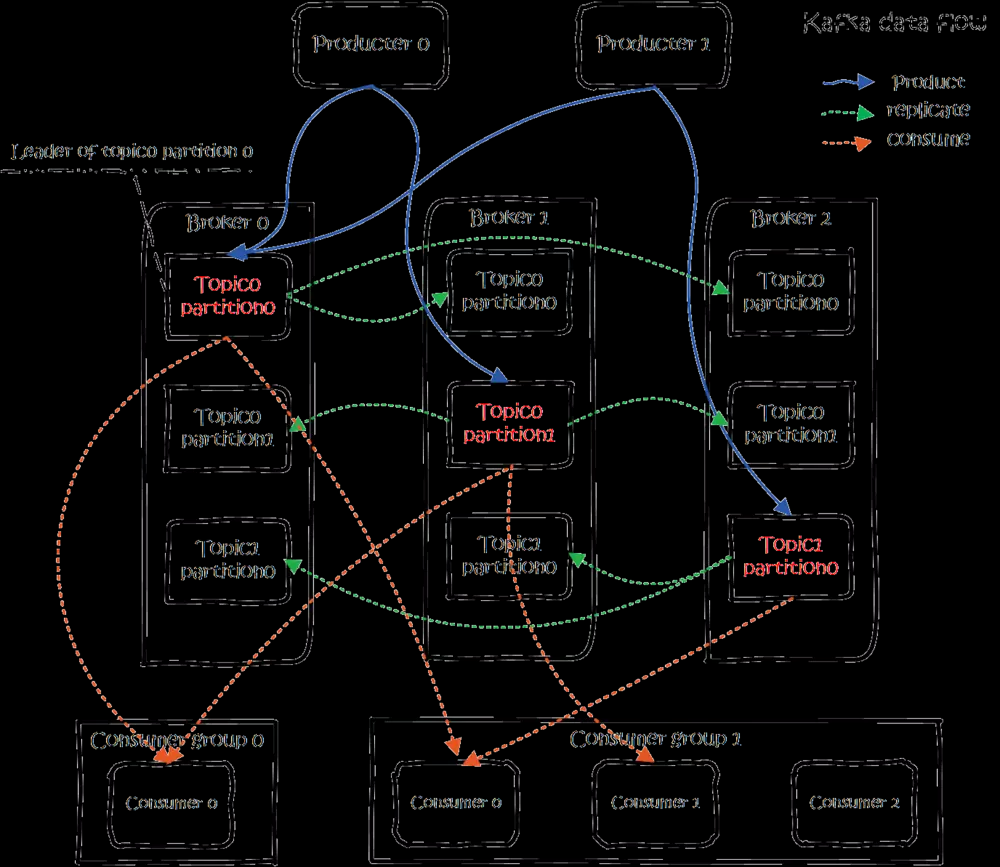
震惊了!原来这才是kafka!
大概用法就是,Producers往Brokers里面的指定Topic中写消息,Consumers从Brokers里面拉去指定Topic的消息,然后进行业务处理。
图中有两个topic,topic 0有两个partition,topic 1有一个partition,三副本备份。可以看到consumer gourp 1中的consumer 2没有分到partition处理,这是有可能出现的,下面会讲到。
关于broker、topics、partitions的一些元信息用zk来存,监控和路由啥的也都会用到zk。
生产过程
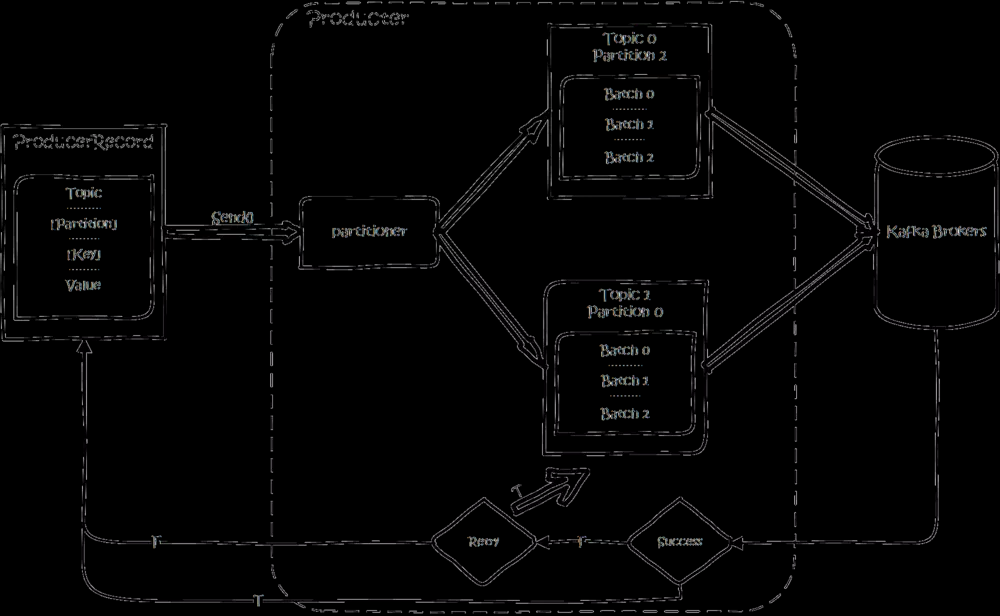
创建一条记录,记录中一个要指定对应的topic和value,key和partition可选。 先序列化,然后按照topic和partition,放进对应的发送队列中。kafka produce都是批量请求,会积攒一批,然后一起发送,不是调send()就进行立刻进行网络发包。
如果partition没填,那么情况会是这样的:
- key有填
按照key进行哈希,相同key去一个partition。(如果扩展了partition的数量那么就不能保证了) - key没填
round-robin来选partition
这些要发往同一个partition的请求按照配置,攒一波,然后由一个单独的线程一次性发过去。
消费过程
订阅topic是以一个消费组来订阅的,一个消费组里面可以有多个消费者。同一个消费组中的两个消费者,不会同时消费一个partition。换句话来说,就是一个partition,只能被消费组里的一个消费者消费,但是可以同时被多个消费组消费。因此,如果消费组内的消费者如果比partition多的话,那么就会有个别消费者一直空闲。
消息投递语义
At most once:最多一次,消息可能会丢失,但不会重复
At least once:最少一次,消息不会丢失,可能会重复
Exactly once:只且一次,消息不丢失不重复,只且消费一次(0.11中实现,仅限于下游也是kafka)
为什么要集成Flume和Kafka
一般使用Flume+Kafka架构都是希望完成实时流式的日志处理,后面再连接上Flink/Storm/Spark Streaming等流式实时处理技术,从而完成日志实时解析的目标。第一、如果Flume直接对接实时计算框架,当数据采集速度大于数据处理速度,很容易发生数据堆积或者数据丢失,而kafka可以当做一个消息缓存队列,从广义上理解,把它当做一个数据库,可以存放一段时间的数据。第二、Kafka属于中间件,一个明显的优势就是使各层解耦,使得出错时不会干扰其他组件。
因此数据从数据源到flume再到Kafka时,数据一方面可以同步到HDFS做离线计算,另一方面可以做实时计算,可实现数据多分发。
- Kafka是pull based, 如果你有很多下游的Data Consumer,用Kafka;
- Kafka有Replication,Flume没有,如果要求很高的容错性(Data High Availability),选kafka;
- 需要更好的Hadoop类产品接口,例如HDFS,HBase等,用Flume。
Spark Streaming 整合FLume
采用推模式:推模式的理解就是Flume作为缓存,存有数据。监听对应端口,如果服务可以链接,就将数据push过去。(简单,耦合要低),缺点是SparkStreaming 程序没有启动的话,Flume端会报错,同时可能会导致Spark Streaming 程序来不及消费的情况。
采用拉模式:拉模式就是自己定义一个sink,SparkStreaming自己去channel里面取数据,根据自身条件去获取数据,稳定性好。
poll方式
1 | 配置文件 |
1 | object FlumePushWordCount |
pull方式
1 | 配置文件 |
1 | object FlumePullWordCount |
Spark Streaming 整合Kafka
Receiver模式 又称kafka高级api模式
构造函数为KafkaUtils.createDstream(ssc,[zk], [consumer group id], [per-topic,partitions] )使用了receivers来接收数据,利用的是Kafka高层次的消费者api,对于所有的receivers接收到的数据将会保存在Spark executors中,然后通过Spark Streaming启动job来处理这些数据,默认会丢失,可启用WAL日志,它同步将接受到数据保存到分布式文件系统上比如HDFS。 所以数据在出错的情况下可以恢复出来 。
简单的理解就是kafka把消息全部封装好,提供给spark去调用,本来kafka的消息分布在不同的partition上面,相当于做了一步数据合并,在发送给spark,故spark可以设置executor个数去消费这部分数据,效率相对慢一些。
Direct模式 又称kafka低级API模式
简单的理解就是spark直接从kafka底层中的partition直接获取消息,相对于Receiver模式少了一步,效率更快。但是这样一来spark中的executor的工作的个数就为kafka中的partition一致,设置再多的executor都不工作,同时偏移量也需要自己维护。
不同于Receiver接收数据,这种方式定期地从kafka的topic下对应的partition中查询最新的偏移量,再根据偏移量范围在每个batch里面处理数据,Spark通过调用kafka简单的消费者Api读取一定范围的数据。
相比基于Receiver方式有几个优点:
A、简化并行
不需要创建多个kafka输入流,然后union它们,sparkStreaming将会创建和kafka分区一种的rdd的分区数,而且会从kafka中并行读取数据,spark中RDD的分区数和kafka中的分区数据是一一对应的关系。
B、高效
第一种实现数据的零丢失是将数据预先保存在WAL中,会复制一遍数据,会导致数据被拷贝两次,第一次是被kafka复制,另一次是写到WAL中。而没有receiver的这种方式消除了这个问题。
C、恰好一次语义(Exactly-once-semantics)
Receiver读取kafka数据是通过kafka高层次api把偏移量写入zookeeper中,虽然这种方法可以通过数据保存在WAL中保证数据不丢失,但是可能会因为sparkStreaming和ZK中保存的偏移量不一致而导致数据被消费了多次。EOS通过实现kafka低层次api,偏移量仅仅被ssc保存在checkpoint中,消除了zk和ssc偏移量不一致的问题。缺点是无法使用基于zookeeper的kafka监控工具
map, mapPartition, flatMap, flatMapToPair 方法
map 函数会对每一条输入进行指定的操作,然后为每一条输入返回一个对象。
MapPartition 函数会对每个分区中的一组数据进行相应的操作,并最终返回一个指定对象的迭代器。
建议使用 MapPartition 取代 Map 函数:优点1:对于 一些初始化操作,如果用map 函数可能需要对每一条数据都进行一次调用,而使用 MapPartition 可以一个分区只调用一次初始化操作,资源使用更高效!!优点2:通过mapPartition 可以非常方便的对返回结果进行过滤 (比如错误数据过滤),map 较难实现。
flatMap 函数则是两个操作的集合——正是“先映射后扁平化”:
- 同map函数一样:对每一条输入进行指定的操作,然后为每一条输入返回一个对象
- 最后将所有对象合并为一个对象
FlatMap 与 Map 的主要区别 :
- Map 主要转换是一条数据 返回 一条数据
- FlatMap 将一条数据转换为 一组数据 (迭代器),主要用于将一条记录转换为多条记录的场景,如对 每行文章中的单词进行切分,返回 每行中所有单词。
flatMapToPair 其实是在FlatMap 函数基础上将返回的数据转换为了 1个Tuple, 即 key-value 格式的数据。方便相同的key 的数据进行后续的统计如统计次数等操作。