Solr介绍
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr可以独立运行在Jetty、Tomcat等这些Servlet容器中。
Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
使用Solr 进行创建索引和搜索索引的实现方法很简单,如下:
- 创建索引:客户端(可以是浏览器可以是Java程序)用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr服务器根据xml文档添加、删除、更新索引 。
- 搜索索引:客户端(可以是浏览器可以是Java程序)用 GET方法向 Solr 服务器发送请求,然后对Solr服务器返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建页面UI的功能,但是Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
Slor的安装启动
下载地址http://lucene.apache.org/solr/
下载完成后解压即可
cmd命令行下切换到解压目录下的bin目录下,启动slor服务,启动的是solr的云服务版,启动命令为
solr -e cloud -noprompt
默认在8983和7574端口启动两组solr服务
当然也可以用下述命令启动单机版的solr:
solr start -p 8983
当需要更多的命令时,可以使用
solr -help
查看更多的命令
启动服务之后在http://localhost:8983就可以打开启动的solr服务
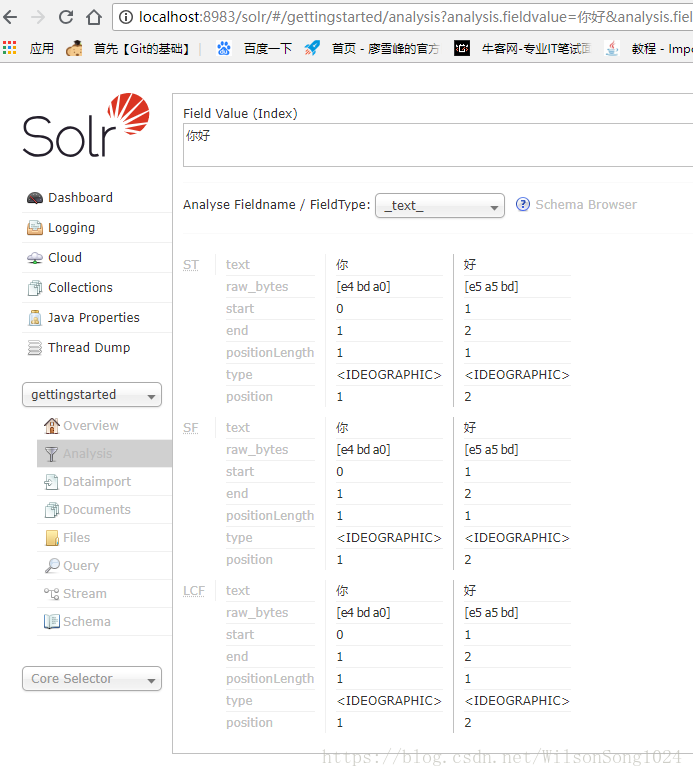
启动服务之后,需要导入相应的数据,命令为:
1 | java -Dc=gettingstarted -Dauto -Drecursive -jar example\exampledocs\post.jar docs\ |
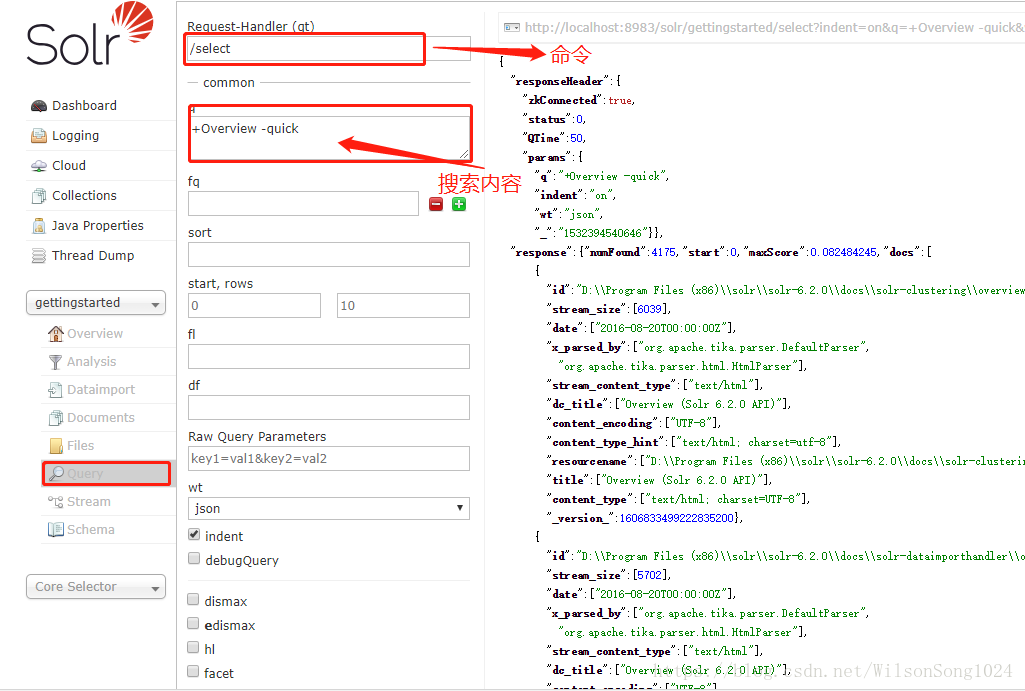
中文分词搜索:IK-Analyzer
(1)关掉上述cloud版的服务,然后打开单机版,默认89893端口打开
(2)创建索引的部署

(3)中文分词
由于slor默认的是英文格式的分词格式,也就是按照空格的方式分词的,因此要实现中文的分词需要做一些修改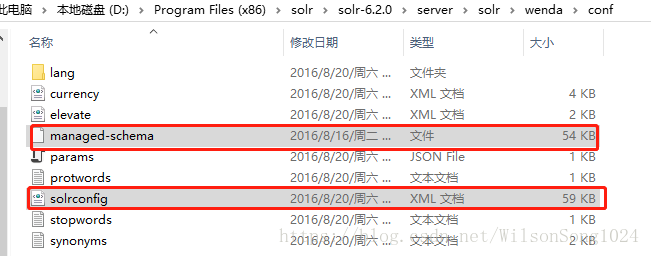
下面两个文件是我们所需要了解的两个配置文件
在managed-schema中添加如下代码端作为中文分词的配置1
2
3
4
5
6
7
8
9
10
11<fieldTypename="text_ik" class="solr.TextField">
<!--索引时候的分词器-->
<analyzer type="index">
<tokenizerclass="org.wltea.analyzer.util.IKTokenizerFactory" useSmart=“false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<!--查询时候的分词器-->
<analyzer type="query">
<tokenizerclass="org.wltea.analyzer.util.IKTokenizerFactory" useSmart=“true"/>
</analyzer>
</fieldType>
索引时候的分词器使用的是useSmart=“false”,这个时候分词分的越细越好
查询时候的分词器使用的是useSmart=“true”,这个时候就是越接近查询的内容越好,查询起来越快
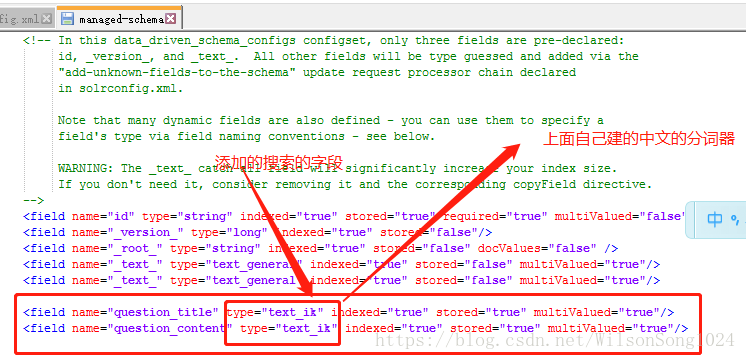
后台的配置因为需要用到中文的分词,所以需要你进行在solrconfig.xml中的lib下添加相应的jar包

重启solr,在solr中就可以看见相应的text_ik的分词器,就是刚才自己定义的text_ik
使用分词之后可以看到和上述的分词的结果是一样的
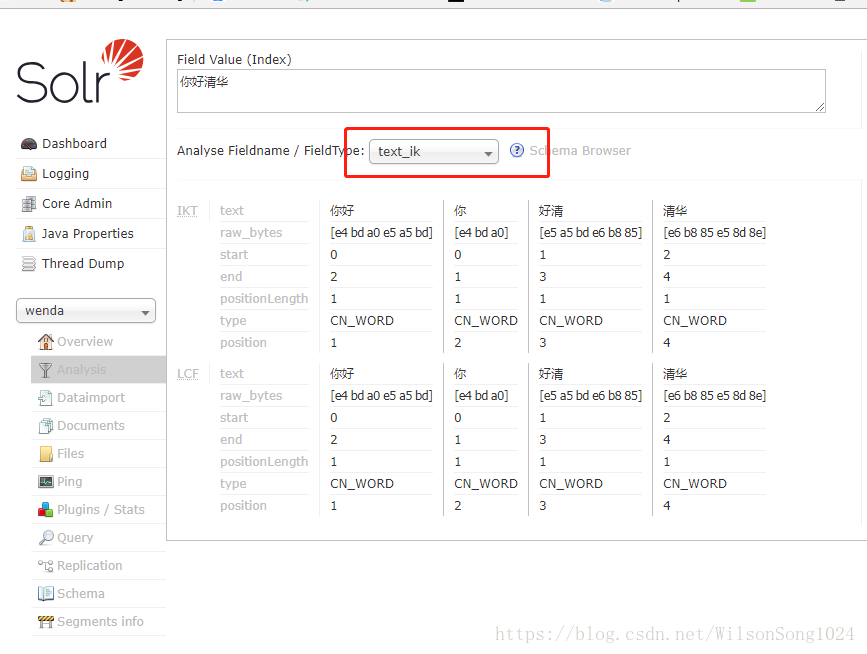
然后搜索的话需要有字典和后台的数据库的内容,然后如何从数据库中把数据导入呢?
数据库相关jar包导入,参考资料:http://wiki.apache.org/solr/DIHQuickStart
首先在solrconfig.xml中添加如下代码行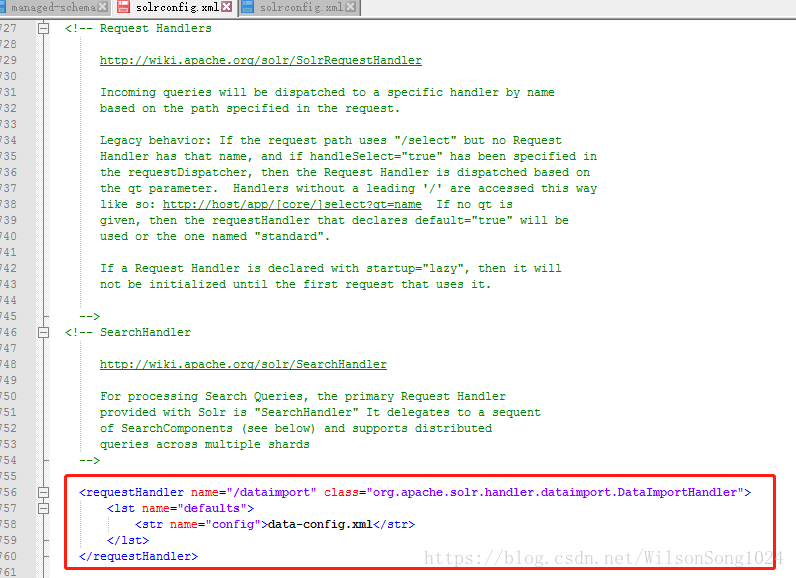
上图中有显示一个data-config.xml的文件,这个是我们需要自己添加并配置的
在你的自己之前建立的wenda的目录文件夹下新建一个data-config.xml,并在文件中添加如下代码段1
2
3
4
5
6
7
8
9
10
11
12
13
14<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost/wenda"
user="root"
password="123456"/>
<document>
<entity name="question"
query="select id,title,content from question">
<field column="title" name="question_title"/>
<field column="content" name="question_content"/>
</entity>
</document>
</dataConfig>
其实上面代码段与你的数据库是一一对应的,这个代码段是在里抄来的,然后根据自己的参数进行修改
url 数据库的本机地址
user 数据库的用户名
password 数据库的密码
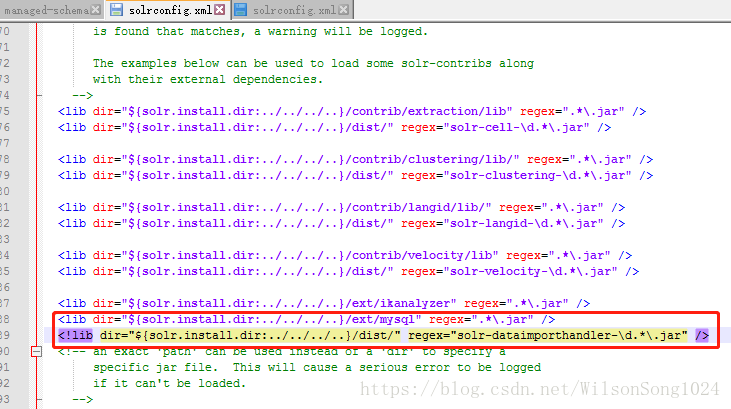
然后重启solr
导入数据库里的数据
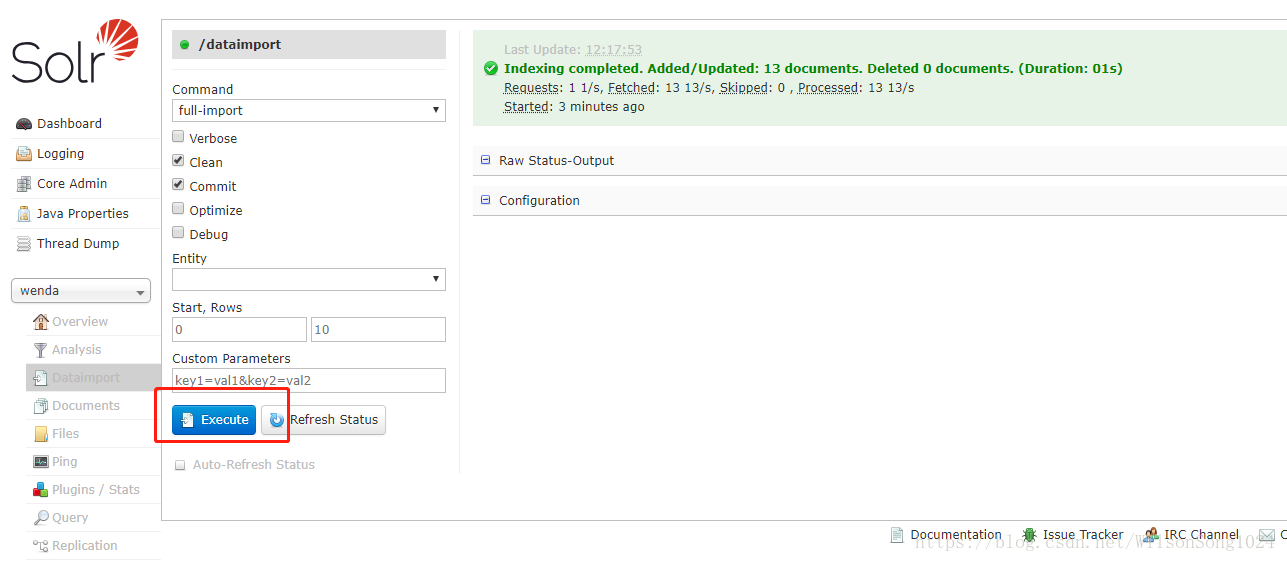
到这里就把solr的服务器搭建并测试成功了
Sringboot中集成solr
(1).pom中添加solrj的Maven依赖1
2
3
4
5
6!-- https://mvnrepository.com/artifact/org.apache.solr/solr-solrj -->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>6.2.0</version>
</dependency>
<
(2)按照dao-service-controller编写服务
因为不涉及数据库的读写,所以就不需要dao层
关于solr的集成按照什么方式去配置,怎么去写,参照
service层
1 | package com.springboot.springboot.service; |
controller层
1 | package com.springboot.springboot.controller; |
这样后端的代码结合前端就写完了,实现solr的集成,然后就可以在你的网站使用solr搜索引擎来搜索
但是面临一个问题,你的slor的库是从数据库中导入的,然后每次出现新的内容,怎么能够实现实时的搜索呢?
有两种方式:
- 使用solr的自动增量导入功能
- 在增加内容的时候使用异步事件把内容实时添加到solr的搜索内容中,具体实现
首先在你增加内容 的时候先产生事件
1 | //添加问题后就产生一个异步的事件,把问题增加进去,然后达到实时搜索的功能 |
1 | package com.springboot.springboot.async.handler; |
这样就通过异步队列实时的将新增添的内容通过service的方式添加到solr的搜索库中,实现实时的搜索。
然后其余的部分,如solr的搜索的原理可以参照