深入了解hbase
集群建备份,它是master/slaves结构式的备份,由master推送,这样更容易跟踪现在备份到哪里了,况且region server是都有自己的WAL 和HLog日志,它就像mysql的主从备份结构一样,只有一个日志来跟踪。一个master集群可以向多个slave集群推送,收到推送的集群会覆盖它本地的edits日志。
这个备份操作是异步的,这意味着,有时候他们的连接可能是断开的,master的变化不会马上反应到slave当中。备份个格式在设计上是和mysql的statement-based replication是一样的,全部的WALEdits(多种来自Delete和Put的Cell单元)为了保持原子性,会一次性提交。
HLogs是region server备份的基础,当他们要进行备份时必须保存在hdfs上,每个region server从它需要的最老的日志开始进行备份,并且把当前的指针保存在zookeeper当中来简化错误恢复,这个位置对于每一个slave 集群是不同的,但是对于同一个队列的HLogs是相同的。
下面这个是设计的结构图
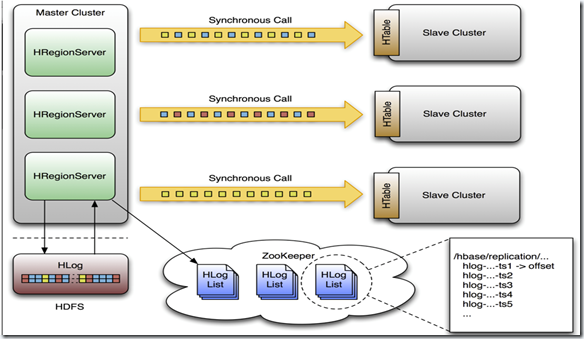
下面我们了解一下master和一个slave节点的整个过程。
(1)当客户端通过api发送Put、Delete或者ICV到region server,这些KeyValue被转换成WALEdit,这个过程会被replication检测到,每一个设置了replication的列族,会把scope添加到edit的日志,然后追加到WAL中,并被应用到MemStore中。
(2)在另一个线程当中,edit被从log当中读取来,并且只有可以备份的KeyValues(列族为scoped为GLOBAL的,并且不是catalog,catalog指的是.META. 和 -ROOT-)
(3-1)这个edit然后被打上master群集的UUID,当buffer写满的时候或者读完文件,buffer会发到slave集群的随机的一个region server同步的,收到他们的region server把edit分开,一个表一个buffer,当所有的edits被读完之后,每一个buffer会通过HTable来flush,edits里面的master集群的UUID被应用到了备份节点,以此可以进行循环备份。
(4-1)回到master的region server上,当前WAL的位移offset已经被注册到了zookeeper上面。
(3-2)这里面,如果slave的region server没有响应,master的region server会停止等待,并且重试,如果目标的region server还是不可用,它会重新选择别的slave的region server去发送那些buffer。
同时WALs会被回滚,并且保存一个队列在zookeeper当中,那些被region server存档的Logs会更新他们在复制线程中的内存中的queue的地址。
(4-2)当目标集群可用了,master的region server会复制积压的日志。
HBase协处理器
简介
总体来说其包含两种协处理器:Observers和Endpoint。
其中Observers可以理解问传统数据库的触发器,当发生某一个特定操作的时候出发Observer。
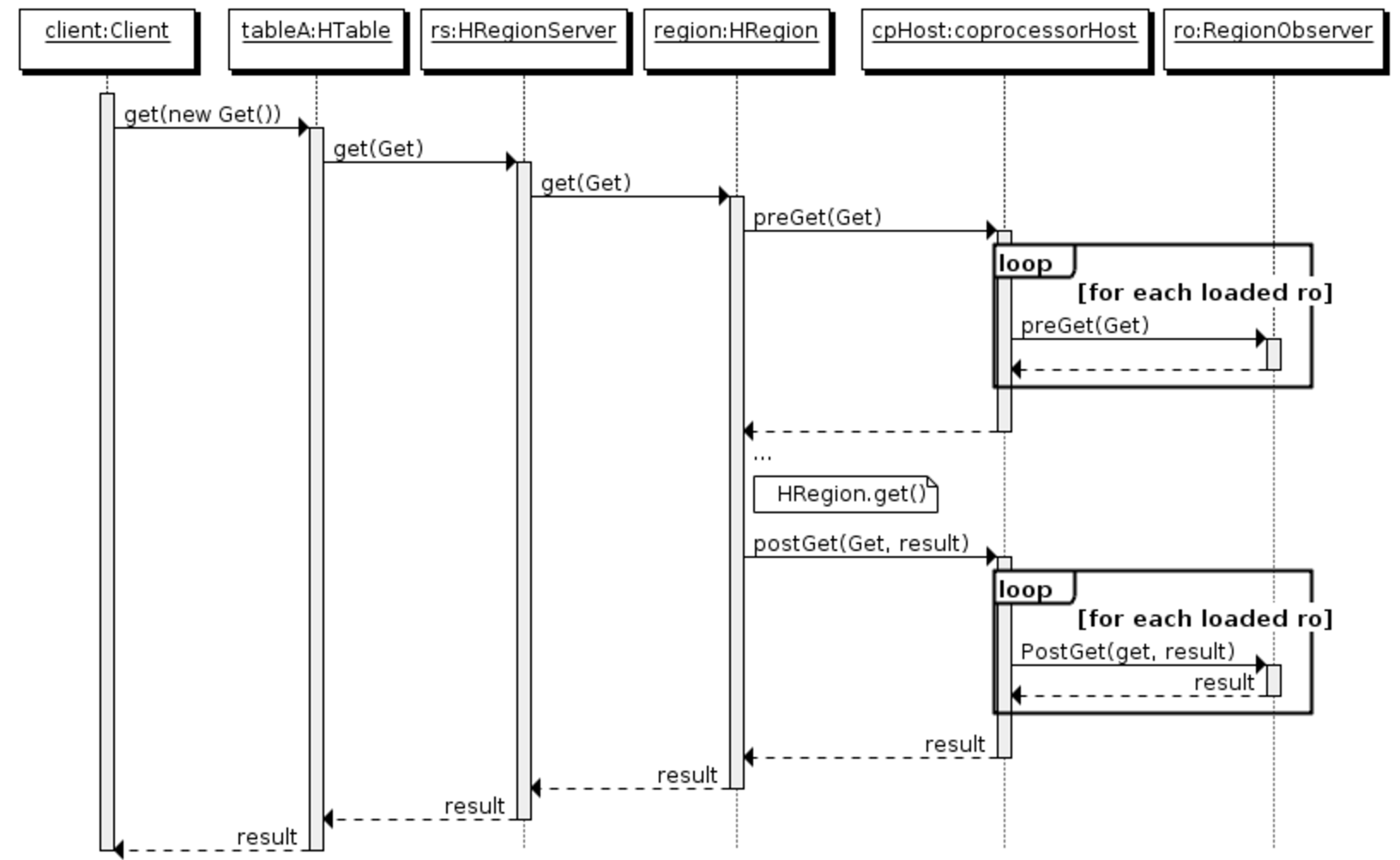
- RegionObserver:提供基于表的region上的Get, Put, Delete, Scan等操作,比如可以在客户端进行get操作的时候定义RegionObserver来查询其时候具有get权限等。具体的方法(拦截点)有:
- preOpen, postOpen: Called before and after the region is reported as online to the master.
- preFlush, postFlush: Called before and after the memstore is flushed into a new store file.
- preGet, postGet: Called before and after a client makes a Get request.
- preExists, postExists: Called before and after the client tests for existence using a Get.
- prePut and postPut: Called before and after the client stores a value.
- preDelete and postDelete: Called before and after the client deletes a - value.
- WALObserver:提供基于WAL的写和刷新WAL文件的操作,一个regionserver上只有一个WAL的上下文。具体的方法(拦截点)有:
- preWALWrite/postWALWrite: called before and after a WALEdit written to WAL.
- MasterObserver:提供基于诸如ddl的的操作检查,如create, delete, modify table等,同样的当客户端delete表的时候通过逻辑检查时候具有此权限场景等。其运行于Master进程中。具体的方法(拦截点)有:
- preCreateTable/postCreateTable: Called before and after the region is reported as online to the master.
- preDeleteTable/postDeleteTable
以上对于Observer的逻辑以RegionObserver举例来说其时序图如下:
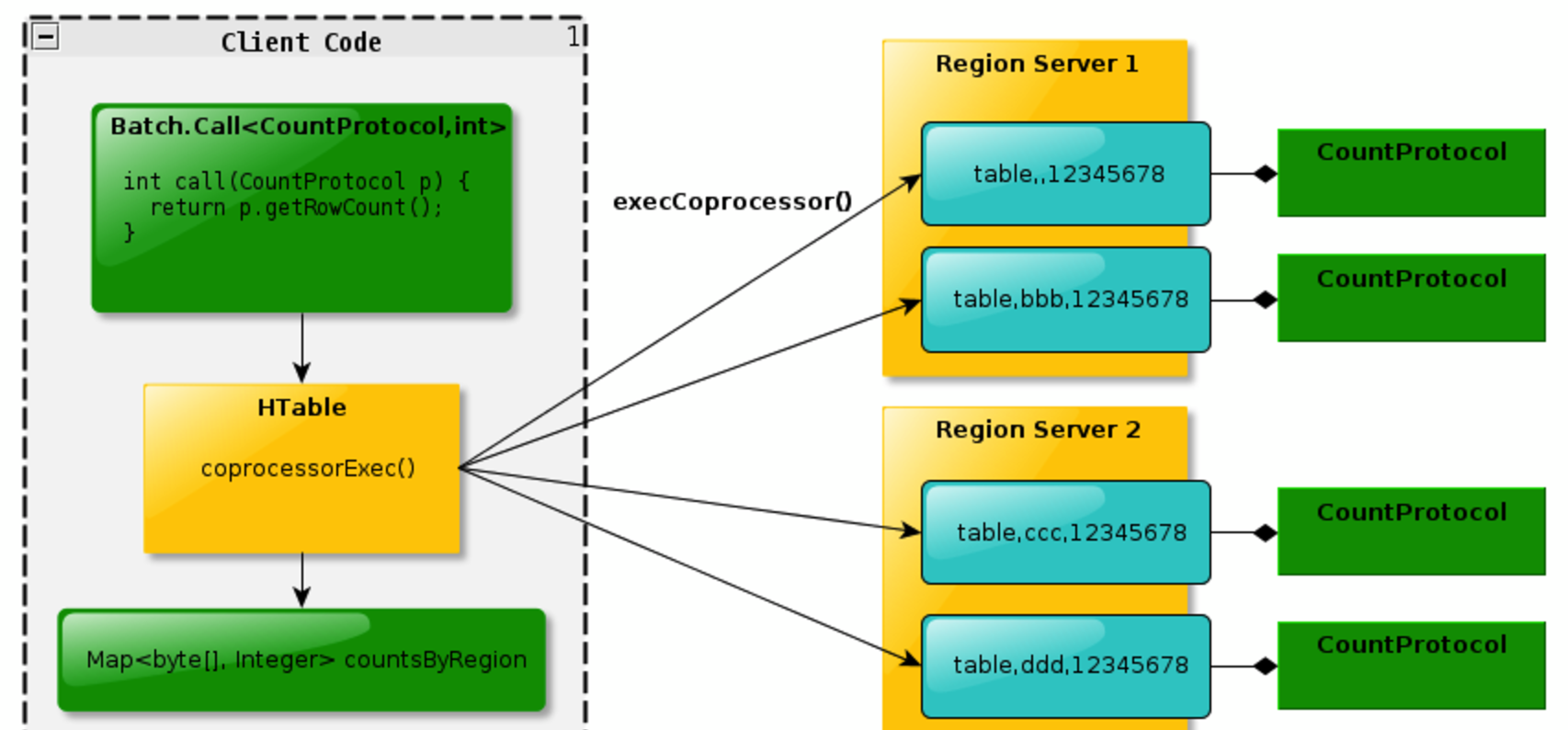
Endpoint可以理解为传统数据库的存储过程操作,比如可以进行某族某列值得加和。无Endpoint特性的情况下需要全局扫描表,通过Endpoint则可以在多台分布有对应表的regionserver上同步加和,在将加和数返回给客户端进行全局加和操作,充分利用了集群资源,增加性能。Endpoint基本概念如下图:
两者代码实现细节的差异
在实现两种协处理器的时候稍有区别。无论哪种协处理器都需要运行于Server端的环境中。其中Endpoint还需要通过protocl来定义接口实现客户端代码进行rpc通信以此来进行数据的搜集归并。而Observer则不需要客户端代码,只在特定操作发生的时候出发服务端代码的实现。
Observer协处理器的实现
相对来说Observer的实现来的简单点,只需要实现服务端代码逻辑即可。通过实现一个RegionserverObserver来加深了解。
所要实现的功能:
假定某个表有A和B两个列——————————–便于后续描述我们称之为coprocessor_table
- 当我们向A列插入数据的时候通过协处理器像B列也插入数据。
- 在读取数据的时候只允许客户端读取B列数据而不能读取A列数据。换句话说A列是只写 B列是只读的。(为了简单起见,用户在读取数据的时候需要制定列名)
- A列值必须是整数,换句话说B列值也自然都是整数
- 当删除操作的时候不能指定删除B列
- 当删除A列的时候同时需要删除B列
- 对于其他列的删除不做检查
在上述功能点确定后,我们就要开始实现这两个功能。好在HBase API中有BaseRegionObserver,这个类已经帮助我们实现了大部分的默认实现,我们只要专注于业务上的方法重载即可。
代码框架:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class 协处理器类名称 extends BaseRegionObserver
{
private static final Log LOG = LogFactory.getLog(协处理器类名称.class);
private RegionCoprocessorEnvironment env = null;// 协处理器是运行于region中的,每一个region都会加载协处理器
// 这个方法会在regionserver打开region时候执行(还没有真正打开)
public void start(CoprocessorEnvironment e) throws IOException
{
env = (RegionCoprocessorEnvironment) e;
}
// 这个方法会在regionserver关闭region时候执行(还没有真正关闭)
public void stop(CoprocessorEnvironment e) throws IOException
{
// nothing to do here
}
/**
* 出发点,比如可以重写prePut postPut等方法,这样就可以在数据插入前和插入后做逻辑控制了。
*/
业务代码实现 :
根据上述需求和代码框架,具体逻辑实现如下。
- 在插入需要做检查所以重写了prePut方法
- 在删除前需要做检查所以重写了preDelete方法
1 | public class MyRegionObserver extends BaseRegionObserver |
Observer协处理器上传加载
完成实现后需要将协处理器类打包成jar文件,对于协处理器的加载通常有三种方法:
- 配置文件加载:即通过hbase-site.xml文件配置加载,一般这样的协处理器是系统级别的,全局的协处理器,如权限控制等检查。
- shell加载:可以通过alter命令来对表进行scheme进行修改来加载协处理器。
- 通过API代码实现:即通过API的方式来加载协处理器。
上述加载方法中,1,3都需要将协处理器jar文件放到集群的hbase的classpath中。而2方法只需要将jar文件上传至集群环境的hdfs即可。
下面我们只介绍如何通过2方法进行加载。
步骤1:通过如下方法创建表1
2hbase(main):001:0> create 'coprocessor_table','F'
0 row(s) in 2.7570 seconds => Hbase::Table - coprocessor_table
步骤2:通过alter命令将协处理器加载到表中1
alter 'coprocessor_table' , METHOD =>'table_att','coprocessor'=>'hdfs://ns1/testdata/Test-HBase-Observer.jar|cn.com.newbee.feng.MyRegionObserver|1001'
其中:’coprocessor’=>’jar文件在hdfs上的绝对路径|协处理器主类|优先级|协处理器参数
上述协处理器并没有参数,所以未给出参数,对于协处理器的优先级不在此做讨论。
步骤3:检查协处理器的加载
1 | hbase(main):021:0> describe 'coprocessor_table' Table coprocessor_table is ENABLED |
可以看到协处理器被表成功加载,其实内部是将update所有此表的region去加载协处理器的。
Hbase读写数据的原理解析
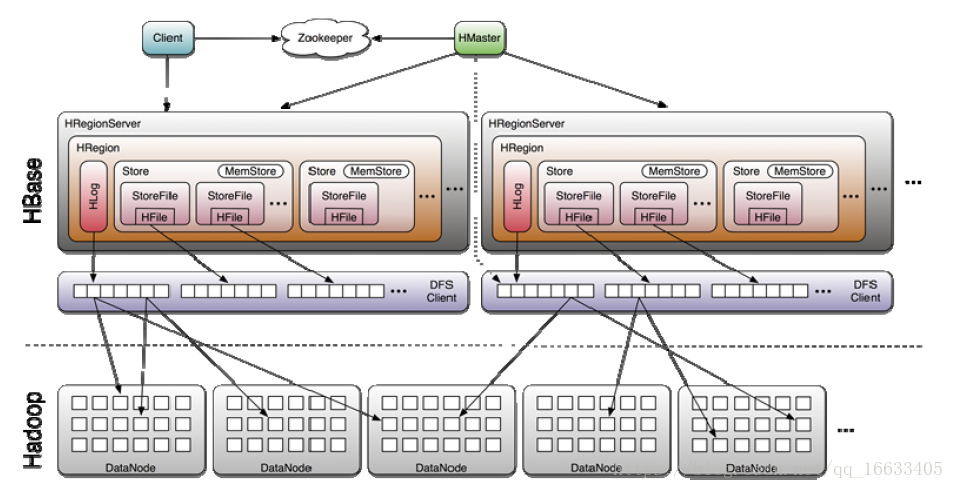
每个列族对应一个store,每个store先存到memstore里
针对上图的一些解释:
这里面数据分区(region)存储是为了查询方便(即因为是集群所以能充分利用磁盘的IO性)。添加数据时,数据先进入Hlog–预写日志(数据只能追加不能修改)<防止数据丢失>,数据在Hlog写完后再写到内存中。
HFile:认为是将数据进行序列化。
StoreFile:认为是一个文件。
DFS:调用HDFS的客户端API来将数据传到HDFS。
写数据的流程(参考上图):
1、客户端向hregionServer请求写数据
2、hregionServer将数据先写入hlog中。
3、hregionServer将数据后写入memstore中。
4、当内存中的数据达到阈值64M的时候,将数据Flush到硬盘中,并同时删除内存和hlog中的历史数据。
5、将硬盘中数据通过HFile来序列化,再将数据传输到HDFS进行存储。并对Hlog做一个标记。
6、当HDFS中的数据块达到4块的时候,Hmaster将数据加载到本地进行一个合并(如果合并后数据的大小小于256M则当数据块再次达到4块时(包含小于256M的数据块)将最新4块数据块再次进行合并,此时数据块大于256M)。
7、若数据块大于256M,则将数据重新拆分,将分配后的region重新分配给不同的hregionServer进行管理。
8、当hregionServer宕机后,将hregionServer上的hlog重新分配给不同的hregionServer进行加载(修改.META文件中关于数据所在server的信息)。注意:hlog会同步到HDFS中。
读数据的流程(参考下图):
1、通过zk来获取ROOT表在那个节点上,然后进一步通过-ROOT表和-META表来获取最终的位置信息。
2、数据从内存和硬盘合并后返回到客户端。
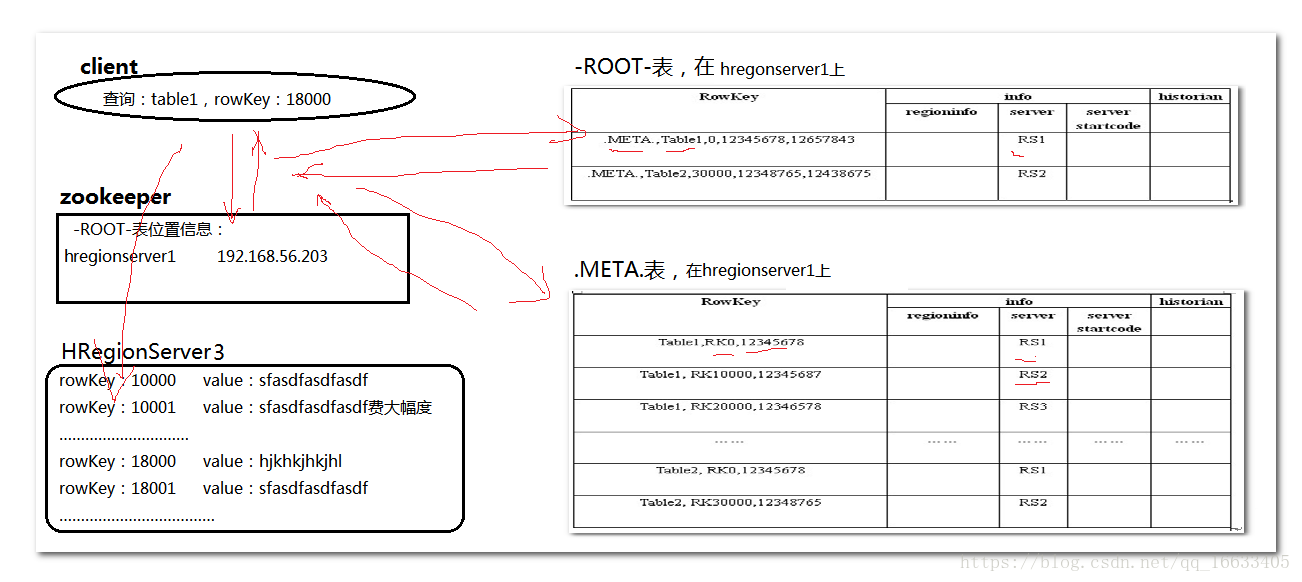
PS:由上图可看到,当客户端在执行查询语句的时候,会先到zk上寻找对应-ROOT表(主要描述-META表在哪里)的位置信息(由此也知道ZK在Hbase中的作用),接下来根据-ROOT表中数据进而找到对应的HRegionServer,在对应的HRegionServer上的-META表(主要记载表的元数据信息)中找到对应的Table表在哪个HRegionServer上,再到对应的HRegionServer中查找对应的数据。
hbase replication原理分析
https://blog.csdn.net/lw_ghy/article/details/60779289
replicationSource大致工作流程
- while(isAlive())进行主体循环
- 从WAL文件获取List<WAL.Entry>
- 通过调用shipEdits方法发送数据
- 调用replicationEndpoint replicate方法发送数据
- 最终调用admin.replicateWALEntry通过rpc发送数据
regionserver如何从slave cluster中选取regionserver当做复制节点
- replication过程需要连接peer(slave cluster),首先要获取这个peer所有活着的regionservers
- 拿到所有regionservers信息之后,开始选择哪些regionservers作为replication的对象
- 选哪些regionservers当做sink由peer活着的regionserver个数*ratio(默认值0.1)决定,regionservers先shuffle打乱顺序后再截取
- 如果选择的sink(regionserver)个数为0,一直等待peer上线,也就是slave cluster没有启动的情况
总结
- 每个slave cluster对应一个replicationSource线程,各个slave复制互不干扰
- 每个replicationSource是单线程进行传输数据,改成多线程并发传可能更好
- 数据是通过rpc发送过去,调用slave cluster regionserver RSRpcServices的replicateWALEntry方法
HBase是强一致性系统
Hbase具有以下特点
- 每个值只出现在一个REGION
- 同一时间一个Region只分配给一个Region服务器
- 行内的mutation操作都是原子的(原子性操作是指:如果把一个事务可看作是一个程序,它要么完整的被执行,要么完全不执行)。
- put操作要么成功,要么完全失败。
当某台region server fail的时候,它管理的region failover到其他region server时,需要根据WAL log(Write-Ahead Logging)来redo(redolog,有一种日志文件叫做重做日志文件),这时候进行redo的region应该是unavailable的,所以hbase降低了可用性,提高了一致性。设想一下,如果redo的region能够响应请求,那么可用性提高了,则必然返回不一致的数据(因为redo可能还没完成),那么hbase就降低一致性来提高可用性了。
crash后
对于分布式数据库来说,容错处理是非常重要的一个部分。RegionServer是HBase系统中存在最多的节点,所以对于RegionServer的容错处理对于HBase来说至关重要。本文对RegionServer的容错处理进行Step by Step的分析,希望能解释清除整个过程并加以点评。
我们假设在HBase运行的过程中有一个RegionServer突然Crash, 基于这个场景进行分析。
1. RegionServer Crash了
Crash的原因可能有很多种,程序自身挂掉,OS挂掉,网络断掉,电源断掉,等等。但从MasterServer的角度看来只有一种现象,那就是RegionServer在Zookeeper上面注册的Node消失了。我们知道当RegionServer启动的时候会产生一个StartCode,并在Zookeeper上面注册一个EPHEMERAL类型的节点。
一旦RS和ZK之间的通信消失,EPHEMERAL的节点就会被自动删除。而MasterServer则会捕获这个Node消失的事件。
捕获这个事件之后,所有的事情就交给ServerManager.expireServer()来处理了。

2. ServerManager处理
首先ServerManager会更新自己的列表,包括deadserver list, online server list 以及 server connection list. 当然在我们试图Stop整个Cluster的时候也会收到同样的请求,不予理睬就好了。
并不是所有的RS Crash都做相同的处理,有些RS比较特殊,他们正在管理-ROOT-表或者.META.表。如果我们重新分配Region, 就需要修改.META.表,如果要访问.META.表先要查询-ROOT-表 (参见以前的文章,client如何路由到正确的RS)。问题是现在管理-ROOT-表或者.META.表的RS挂了,显然第一要务是让-ROOT-和.META.有所归属,能够正常的对他们进行读写。
接下来ServerManager通过传递Event的方式将任务交给Excutor线程来处理,具体调用MetaServerShutdownHandler或者ServerShutdownHandler的process函数。
3. ServerShutdownHandler处理
MetaServerShutdownHandler是继承于ServerShutdownHandler的,除了打上META的标志以外其他都一样,所以我们只介绍ServerShutdownHandler的处理。
处理的第一步是Split HLog。当RS Crash的时候所有MemCache里面的内容都会被丢掉,这些内容还没有来得及Flush到HFile里面。感谢WAL机制,所有的内容都可以在HLog File里面找到。问题是原来管理这些HLog文件的RS已经挂掉了,需要将这些HLog交给新的RS去处理。往往这些HLog不会交给同一个新的RS去处理,因为HLog可能包含多个Region的内容,而这些Region可能会分配给不同的RS。这样看来最好的方式是让HLog里面的每一个Entry跟随Region,Region被分配给哪个RS,就让那个RS来处理这个Entry。事实上MasterServer也确实是这么做的。具体步骤如下:
1) 从Crash的RS的HLog目录下读取每个HLog文件
2) 根据文件中每个Entry所隶属的Region找到Region文件的存储目录。将Entry写到一个叫做 “recovered.edits” 的文件夹中。Entry写入的格式依然是HLog的格式。
3) 将Region分配给某个具体的RS,剩下的任务由RS处理
4. Assign RegionServer
前面有提到过,如果Crash的RS正在Handle -ROOT-或者.META.,需要特殊处理。特殊处理的方式就是先assign -ROOT-和.META.,并等待他们online。这样可以保证后需的assign工作。
具体Assign的过程可以单独用一章来讲,这里不做详细介绍。
5. RegionServer加载新的Region
一旦某个RS被assign了一个新的Region, 它就会试图加载这个新Region. 在加载的过程中RS会查看 “recovered.edits” 目录,试图从HLog中恢复丢失的数据。具体过程如下:
1) 扫描目录中的每个HLog文件
2) 跳过那些Sequence ID小于Region MAX Seq ID的Entry,因为这些Entry已经在HFile里面了。
3) 找到丢失的Entry并写入MemStore
4) Flush MemStore到HFile
5) 删除目录下的文件
具体可以参考 HRegion.replayRecoveredEdits
6. 分析后的思考
写到这里整个过程已经基本上结束了,但除了分析过程,还有许多我们可以思考的地方。
1) 恢复一个RegionServer需要多少时间?
等待ZK Node消失 + Split Log + Assign Region + Recover HLog +Region Online
这是从正常情况看来需要花费的时间,Log越多,Region越多,需要花费的时间越长。别忘了如果RS正在Handle -ROOT-或者.META.,需要的时间会更多。
2) RegionServer的问题真的可以都被侦测吗?
如果RS已经停止服务,但依然存活,ZK Node 就不会消失,这种情况应该发生过。目前只能作为Bug去修理。也许额外的Monitor是一个弥补的办法(定期Scan什么的)。
3) 容错性到底有多强?
如果是RS接二连三的挂掉,刚刚分配的RS又挂掉,等等极端情况,HBase的容错性到底有多强呢?也许需要针对性的理论分析和详细测试。
。。。
HBase检测宕机是通过Zookeeper实现的, 正常情况下RegionServer会周期性向Zookeeper发送心跳,一旦发生宕机,心跳就会停止,超过一定时间(SessionTimeout)Zookeeper就会认为RegionServer宕机离线,并将该消息通知给Master。上述步骤中比较特殊的是HLog切分,其他步骤相信都能够理解,为什么需要切分HLog?大家都知道当前(0.98)版本中一台RegionServer只有一个HLog文件,即所有Region的日志都是混合写入该HLog的,然而,回放日志是以Region为单元进行的,一个Region一个Region回放,因此在回放之前首先需要将HLog按照Region进行分组,每个Region的日志数据放在一起,方便后面按照Region进行回放。这个分组的过程就称为HLog切分。
根据实现方式的不同,HBase的故障恢复前后经历了三种不同模式,
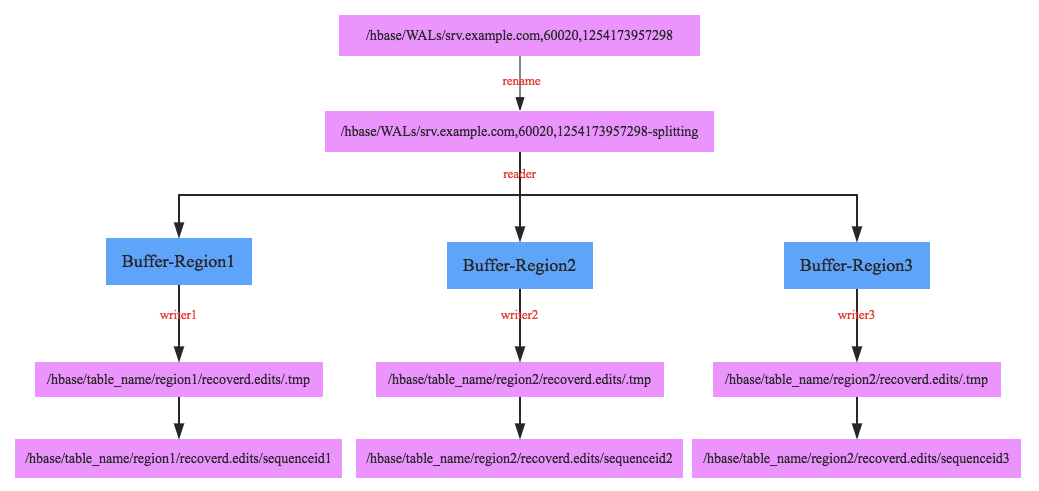
1. 将待切分日志文件夹重命名,为什么需要将文件夹重命名呢?这是因为在某些场景下RegionServer并没有真正宕机,但是HMaster会认为其已经宕机并进行故障恢复,比如最常见的RegionServer发生长时间Full GC,这种场景下用户并不知道RegionServer宕机,所有的写入更新操作还会继续发送到该RegionServer,而且由于该RegionServer自身还继续工作所以会接收用户的请求,此时如果不重命名日志文件夹,就会发生HMaster已经在使用HLog进行故障恢复了,但是RegionServer还在不断写入HLog
2. 启动一个读线程依次顺序读出每个HLog中所有<HLogKey,WALEdit>数据对,根据HLogKey所属的Region不同写入不同的内存buffer中,如上图Buffer-Region1内存存放Region1对应的所有日志数据,这样整个HLog所有数据会被完整group到不同的buffer中
3. 每个buffer会对应启动一个写线程,负责将buffer中的数据写入hdfs中(对应的路径为/hbase/table_name/region/recoverd.edits/.tmp),再等Region重新分配到其他RegionServer之后按顺序回放对应Region的日志数据。