在 NLP 中一般会用其存储大量的字典字符以用于文本的快速分词;除此之外,典型应用场景还包括大批量文本的:词频统计、字符串查询和模糊匹配(比如关键词的模糊匹配)、字符串排序等任务;由于 Trie 大幅降低了无谓的字符串比较,因此在执行上述任务时,其效率非常的高。
Trie 树的简介
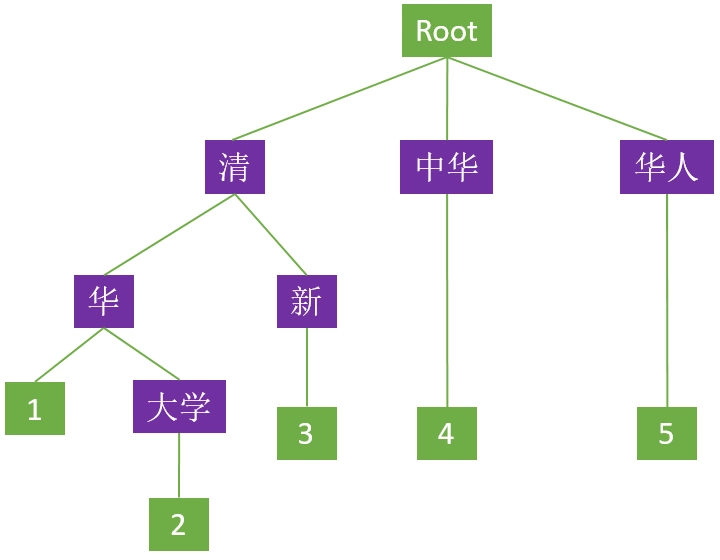
Trie 树中文名叫字典树、前缀树(个人比较喜欢这个名字,看完下文就会明白)等等。这些名字暗示其与字符的处理有关,事实也确实如此,它主要用途就是将字符串(当然也可以不限于字符串)整合成树形。我们先来看一下由“清华”、“清华大学”、“清新”、“中华”、“华人”五个中文词构成的 Trie 树形(为了便于叙述,下文提到该实例,以“例树”简称):
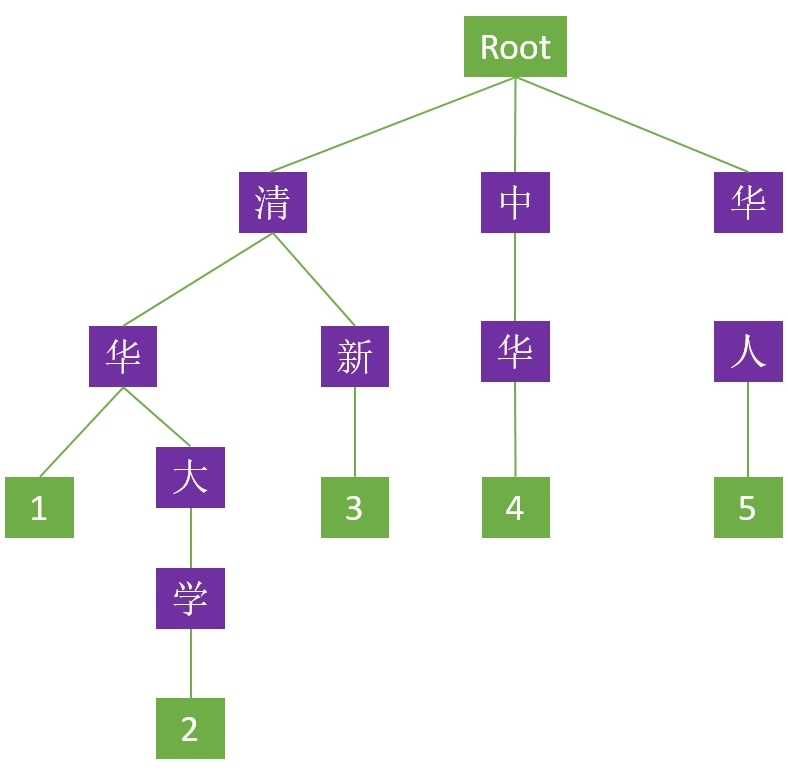
这个树里面每一个方块代表一个节点,其中 ”Root” 表示根节点,不代表任何字符;紫色代表分支节点;绿色代表叶子节点。除根节点外每一个节点都只包含一个字符。从根节点到叶子节点,路径上经过的字符连接起来,构成一个词。而叶子节点内的数字代表该词在字典树中所处的链路(字典中有多少个词就有多少条链路),具有共同前缀的链路称为串。除此之外,还需特别强调 Trie 树的以下几个特点:
- 具有相同前缀的词必须位于同一个串内;例如“清华”、“清新”两个词都有“清”这个前缀,那么在 Trie 树上只需构建一个“清”节点,“华”和“新”节点共用一个父节点即可,如此两个词便只需三个节点便可存储,这在一定程度上减少了字典的存储空间。
- Trie 树中的词只可共用前缀,不可共用词的其他部分;例如“中华”、“华人”这两个词虽然前一个词的后缀是后一个词的前缀,但在树形上必须是独立的两条链路,而不可以通过首尾交接构建这两个词,这也说明 Trie 树仅能依靠公共前缀压缩字典的存储空间,并不能共享词中的所有相同的字符;当然,这一点也有“例外”,对于复合词,可能会出现两词首尾交接的假象,比如“清华大学”这个词在上例 Trie 树中看起来似乎是由“清华”、“大学”两词首尾交接而成,但是叶子节点的标识已经明确说明 Trie 树里面只有”清华“和”清华大学“两个词,它们之间共用了前缀,而非由“清华”和”大学“两词首尾交接所得,因此上例 Trie 树中若需要“大学”这个词则必须从根节点开始重新构建该词。
- Trie 树中任何一个完整的词,都必须是从根节点开始至叶子节点结束,这意味着对一个词进行检索也必须从根节点开始,至叶子节点才算结束。
搜索 Trie 树的时间复杂度
在 Trie 树中搜索一个字符串,会从根节点出发,沿着某条链路向下逐字比对字符串的每个字符,直到抵达底部的叶子节点才能确认字符串为该词,这种检索方式具有以下两个优点:
- 公共前缀的词都位于同一个串内,查词范围因此被大幅缩小(比如首字不同的字符串,都会被排除)。
- Trie 树实质是一个有限状态自动机((Definite Automata, DFA),这就意味着从 Trie 树的一个节点(状态)转移到另一个节点(状态)的行为完全由状态转移函数控制,而状态转移函数本质上是一种映射,这意味着:逐字搜索 Trie 树时,从一个字符到下一个字符比对是不需要遍历该节点的所有子节点的。对于确定性有限自动机感兴趣的同学,可以看看以下引用:
1 | 确定的有限自动机 M 是一个五元组: |
这两个优点相结合可以最大限度地减少无谓的字符比较,使得搜索的时间复杂度理论上仅与检索词的长度有关:O(m),其中 m 为检索词的长度。
Trie 树的缺点
综上可知, Trie 树主要是利用词的公共前缀缩小查词范围、通过状态间的映射关系避免了字符的遍历,从而达到高效检索的目的。这一思想有赖于字符在词中的前后位置能够得到表达,因此其设计哲学是典型的“以信息换时间”,当然,这种优势同样是需要付出代价的:
由于结构需要记录更多的信息,因此 Trie 树的实现稍显复杂。好在这点在大多数情况下并非不可接受。
Trie 型词典不仅需要记录词,还需要记录字符之间、词之间的相关信息,因此字典构建时必须对每个词和字逐一进行处理,而这无疑会减慢词典的构建速度。对于强调实时更新的词典而言,这点可能是致命的,尤其是采用双数组实现的 Trie 树,更新词典很大概率会造成词典的全部重构,词典构建过程中还需处理各种冲突,因此重构的时间非常长,这导致其大多用于离线;不过也有一些 Trie 可以实现实时更新,但也需付出一定的代价,因此这个缺点一定程度上影响了 Trie 树的应用范围。
公共前缀虽然可以减少一定的存储空间,但 Trie 树相比普通字典还需表达词、字之间的各种关系,其实现也更加复杂,因此实际空间消耗相对更大(大多少,得根据具体实现而定)。尤其是早期的“Array Trie”,属于典型的以空间换时间的实现,(其实 Trie 本身的实现思想是是以信息换时间,而非以空间换时间,这就给 Trie 树的改进提供了可能),然而 Trie 树现今已经得到了很好的改进,总体来说,对于类似词典这样的应用,Trie 是一个优秀的数据结构。
Trie 树的几种实现
Array Trie 树
很多文章里将这种实现称为“标准 Trie 树”,但其实它只是 Trie 众多实现中的一种而已,由于这种实现结构简单,检索效率很好,作为讲解示例很不错,因此特地改称其为“经典 Trie 树”,这里引用一下别人家的示例图:
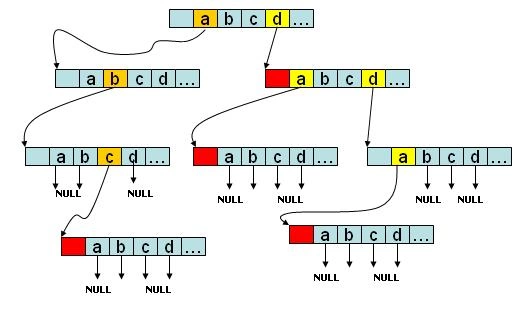
如上图,abc、d、da、dda 四个字符串构成的 Trie 树,如果是字符串会在节点的尾部进行标记。没有后续字符的 branch 分支指向NULL。这种实现的特点是:每个节点都由指针数组存储,每个节点的所有子节点都位于一个数组之中,每个数组都是完全一样的。对于英文而言,每个数组有27个指针,其中一个作为词的终结符,另外 26 个依次代表字母表中的一个字母,对应指针指向下一个状态,若没有后续字符则指向NULL。由于数组取词的复杂度为O(1),因此这种实现的 Trie 树效率非常的高,比如要在一个节点中写入字符“c”,则直接在相应数组的第三个位置标入状态即可,而要确定字母“b”是否在现有节点的子节点之中,检查子节点所在数组第二个元素是否为空即可,这种实现巧妙的利用了等长数组中元素位置和值的一一对应关系,完美的实现了了寻址、存值、取值的统一。
但其缺点也很明显,它强制要求链路每一层都要有一个数组,每个数组都必须等长,这在实际应用中会造成大多数的数组指针空置(从上图就可以看出),事实上,对于真实的词典而言,公共前缀相对于节点数量而言还是太少,这导致绝大多数节点下并没有太多子节点。而对于中文这样具有大量单字的语言,若采取这样的实现,空置指针的数量简直不可想象。因此,经典 Trie 树是一种典型的以“空间换时间”的实现方式。一般只是拿来用于课程设计和新手练习,很少实际应用。
List Trie 树
由于数组的长度是不可变,因此经典 Trie 树存在着明显的空间浪费。但是如果将每一层都换成可变数组(不同语言对这种数据结构称呼不同,比如在 Python 中为List,C# 称为 LinkedList)来存储节点(见下图),每层可以根据节点的数量动态调整数组的长度,就可以避免大量的空间浪费。
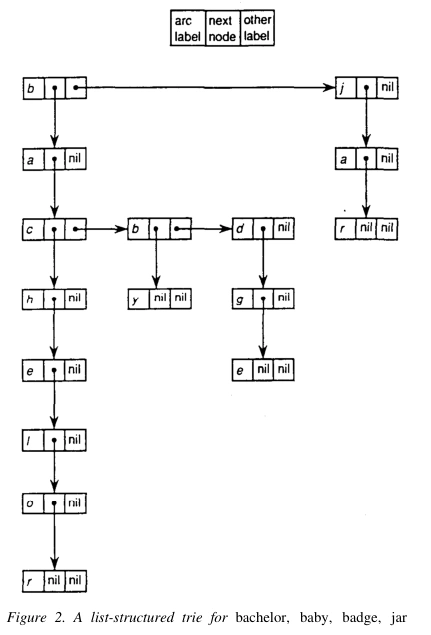
但是可变长数组的取词复杂度是O(d),其中 d 为数组的长度,这意味着状态转移函数无法通过映射转移到下一节点,必须先遍历数组,找到节点后再做转移,因此Trie 树实际时间复杂度变为O(m*n)(其中n为每层数组中节点的数量)。这显然降低了查询效率,因此还算不上完善。
Hash Trie 树
可变数组取词速度太慢,于是就有人想起用一组键值对(Java中可用HashMap类型,Python 中为 dict 类型,C#为Dictionary类型)代替可变数组:其中每个节点包含一组 Key-Value,每个 Key 对应该节点下的一个子节点字符,value 则指向相应的后一个状态。这种方式可以有效的减少空间浪费,同时由于键值对本质上就是一个哈希实现,因此理论上其查词效率也很高(理想状态下取词复杂度为O(1))。
但是哈希有的缺点,这种实现的 Trie 树也会有:
- 为了尽可能的避免键值冲突,哈希表需要额外的空间避开碰撞,因此仍有一部分的空间会被浪费;
- 哈希表很难做到完美,尤其是数据体量增大之后,其查词复杂度常常难以维持在O(1),同时,对哈希值的计算也需要额外的时间,因此实际查询效率要比经典实现低,其具体复杂度由相应的哈希实现来定。
与数组和可变数组实现相比,这种实现做到了空间和时间上的一种平衡,这个结果并不意外,因为哈希表本身就是平衡数组(查寻迅速、增删悲剧)和可变数组(增删迅速,查询悲剧)相应优点和缺点的一种数据结构。
总体而言,Hash Trie 结构简单,性能堪用,而且由于哈希实现可以为每个节点分配唯一的id,因此可以做到节点的实时动态添加(这点是非常大的优势)因此对于中小规模的词典或者对词典的实时更新有需求的应用,该实现非常适合。
Double-array Trie 树
双数组 Trie 树是目前 Trie 树各种实现中性能和存储空间均达到很好效果的实现。但其完整的实现比较复杂,对于新手而言入手相对较难,因此本节将花费较多的篇幅对其解读。
Base Array 的作用
双数组 Trie 树和经典 Trie 树一样,也是用数组实现 Trie 树。只不过它是将所有节点的状态都记录到一个数组之中(Base Array),以此避免数组的大量空置。以行文开头的示例为例,每个字符在 Base Array 中的状态可以是这样子的:
为了能使单个数组承载更多的信息,Base Array 仅仅会通过数组的位置记录下字符的状态(节点),比如用数组中的位置 2 指代“清”节点、 位置 7 指代 “中”节点;而数组中真正存储的值其实是一个整数,这个整数我们称之为“转移基数”,比如位置2的转移基数为 base[2]=3位置7的转移基数为base[7]=2,因此在不考虑叶子节点的情况下, Base Array 是这样子的:

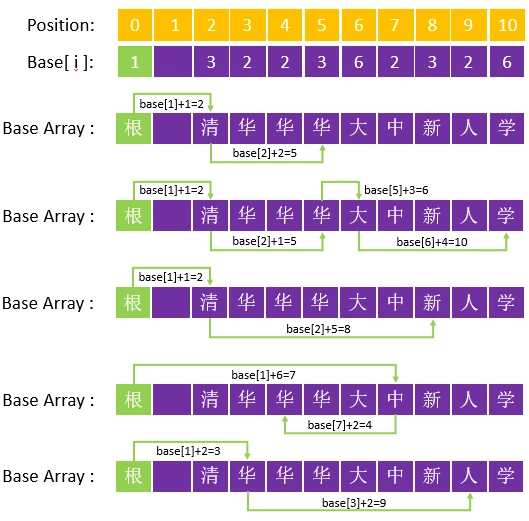
转移基数是为了在一维数组中实现 Trie 树中字符的链路关系而设计的,举例而言,如果我们知道一个词中某个字符节点的转移基数,那么就可以据此推断出该词下一个节点在 Base Array 中的位置:比如知道 “清华”首字的转移基数为base[2]=3,那么“华”在数组中的位置就为base[2]+code("华"),这里的code("华")为字符表中“华”的编码,假设例树的字符编码表为:
清-1,华-2,大-3,学-4,新-5,中-6,人-7
那么“华”的位置应该在Base Array 中的的第 5 位(base[2]+code("华")=3+2=5):

而所有词的首字,则是通过根节点的转移基数推算而来。因此,对于字典中已有的词,只要我们每次从根节点出发,根据词典中各个字符的编码值,结合每个节点的转移基数,通过简单的加法,就可以在Base Array 中实现词的链路关系。以下是“清华”、“清华大学”、“清新”、“中华”、“华人”五个词在 Base Array 中的链路关系:
Base Array 的构造
可见 Base Array 不仅能够表达词典中每个字符的状态,而且还能实现高效的状态转移。那么,Base Array 又是如何构造的呢?
事实上,同样一组词和字符编码,以不同的顺序将字符写入 Trie 树中,获得的 Base Array 也是不同的,以“清华”、“清华大学”、“清新”、“中华”、“华人”五个词,以及字符编码:[清-1,华-2,大-3,学-4,新-5,中-6,人-7] 为例,在不考虑叶子节点的情况下,两种处理方式获得的 base array 为:
首先依次处理“清华”、“清华大学”、“清新”、“中华”、“华人”五个词的首字,然后依次处理所有词的第二个字…直到依次处理完所有词的最后一个字,得到的 Base Array 为:

依次处理“清华”、“清华大学”、“清新”、“中华”、“华人”五个词中的每个字,得到的 Base Array 为:

可以发现,不同的字符处理顺序,得到的 Base Array 存在极大的差别:两者各状态的转移基数不仅完全不同,而且 Base Array 的长度也有差别。然而,两者获得的方法却是一致的,下面以第一种字符处理顺序讲解一下无叶子节点的 Base Array 构建:
- 首先人为赋予根节点的转移基数为
1(可自定义,详见下文),然后依次将五个词中的首字”清”、“中”、“华”写入数组之中,写入的位置由base[1]+code(字符)确定,每个位置的转移基数(base[i])等于上一个状态的转移基数(此例也即base[1]),这个过程未遇到冲突,最终结果见下图: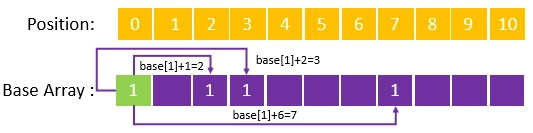
然后依次处理每个词的第二个字,首先需要处理的是“清华”这个词的“华”字,程序先从根节点出发,通过base[1]+code(“清”)=2找到“清”节点,然后以此计算“华”节点应写入的位置,通过计算base[2]+code(“华”)=3寻找到位置 3,却发现位置3已有值,于是后挪一位,在位置4写入“华”节点,由于“华”节点未能写入由前驱节点“清”预测的位置,因此为了保证通过“清”能够找到“华”,需要重新计算“清”节点的转移基数,计算公式为4-code(“华”)=2,获得新的转移基数后,改写“清”节点的转移基数为2,然后将“华”节点的转移基数与“清”节点保持一致,最终结果为:
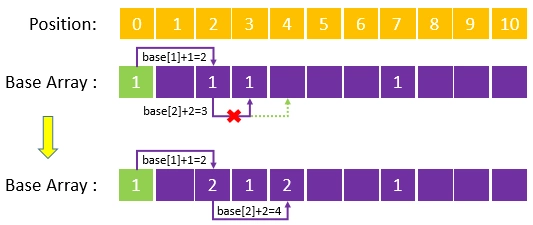
- 重复上面的步骤,最终获得整个 Base Array:

通过以上步骤,可以发现 base array 的构造重点在于状态冲突的处理,对于双数组 Trie 而言,词典构造过程中的冲突是不可避免的,冲突的产生来源于多词共字的情况,比如“中华”、“清华”、“华人”三个词中都有“华”,虽然词在 Trie 树中可以共用前缀,但是对于后缀同字或者后缀与前缀同字的情况却只能重新构造新的节点,这势必会导致冲突。一旦产生冲突,那么父节点的转移基数必须改变,以保证基于前驱节点获得的位置能够容纳下所有子节点(也即保证 base[i]+code(n1)、base[i]+code(n2)、base[i]+code(n3)….都为空,其中n1、n2、n3...为父节点的所有子节点字符,base[i]为父节点新的转移基数,i为父节在数组中的位置)这意味着其他已经构造好的子节点必须一并重构。
因此,双数组 Trie 树的构建时间比较长,有新词加入,运气不好的话,还可能能导致全树的重构:比如要给词典添加一个新词,新词的首字之前未曾写入过,现在写入时若出现冲突,就需要改写根节点的转移基数,那么之前构建好的词都需要重构(因为所有词的链路都是从根节点开始)。上例中,第二种字符写入顺序就遇到了这个问题,导致在词典构造过程中,根节点转移基数被改写了两次,全树也就被重构了三次:
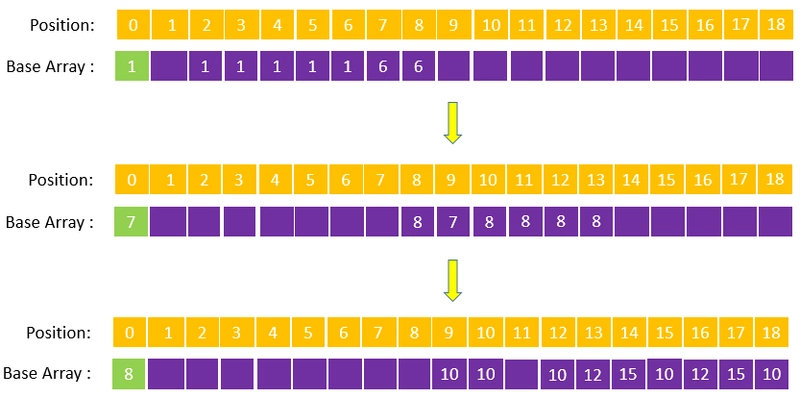
可见不同的节点构建顺序,对 Base Aarry 的构建速度、空间利用率都有影响。建议实际应用中应首先构建所有词的首字,然后逐一构建各个节点的子节点,这样一旦产生冲突,可以将冲突的处理局限在单个父节点和子节点之间,而不至于导致大范围的节点重构。
叶子节点的处理
上面关于 Base Array 的叙述,只涉及到了根节点、分支节点的处理,事实上,Base Array 同样也需要负责叶子节点的表达,但是由于叶子节点的处理,具体的实现各不一致,因此特地单列一节予以论述。
一般词的最后一个字都不需要再做状态转移,因此有人建议将词的最后一个节点的转移基数统一改为某个负数(比如统一设置为-2),以表示叶子节点,按照这种处理,对于示例而言,base array 是这样的:

但细心的童鞋可能会发现,“清华” 和 “清华大学” 这两个词中,只有“清华大学”有叶子节点,既是公共前缀又是单个词的“清华”实际上无法用这种方法表示出叶子节点。
也有人建议为词典中所有的词增加一个特殊词尾(比如将“清华”这个词改写为“清华\0”),再将这些词构建为树,特殊字符词尾节点的转移基数统一设置设为-2,以此作为每个词的叶子节点[4]。这种方法的好处是不用对现有逻辑做任何改动,坏处是增加了总节点的数量,相应的会增加词典构建的时长和空间的消耗。
最后,个人给出一个新的处理方式:直接将现有 base array 中词尾节点的转移基数取负,而数组中的其他信息不用改变。
以树例为例,处理叶子节点前,Base Array 是这样子的:

处理叶子节点之后,Base Array 会是这样子的:

每个位置的转移基数绝对值与之前是完全相同的,只是叶子节点的转移基数变成了负数,这样做的好处是:不仅标明了所有的叶子节点,而且程序只需对状态转移公式稍加改变,便可对包括“清华”、“清华大学”这种情况在内的所有状态转移做一致的处理,这样做的代价就是需要将状态转移函数base[s]+code(字符)改为|base[s]|+code(字符),意味着每次转移需要多做一次取绝对值运算,不过好在这种处理对性能的影响微乎其微。
对此,其他童鞋若有更好的想法, 欢迎在底部留言!
Check Array 的构造
“双数组 Trie 树”,必定是两个数组,因此单靠 Base Array 是玩不起来的….上面介绍的 Base Array 虽然解决了节点存储和状态转移两个核心问题,但是单独的 Base Array 仍然有个问题无法解决:
Base Array 仅仅记录了字符的状态,而非字符本身,虽然在 Base Array,字典中已有的任意一个词,其链路都是确定的、唯一的,因此并不存在歧义;但是对于一个新的字符串(不管是检索字符串还是准备为字典新增的词),Base Array 是不能确定该词是否位于词典之中的。对于这点,我们举个例子就知道了:

如果我们要在例树中确认外部的一个字符串“清中”是否是一个词,按照 Trie 树的查找规则,首先要查找“清”这个字,我们从根节点出发,获得|base[1]|+code(“清”)=3,然后转移到“清”节点,确认清在数组中存在,我们继续查找“中”,通过|base[3]|+code(“中”)=9获得位置9,字符串此时查询完毕,根据位置9的转移基数base[9]=-2确定该词在此终结,从而认为字符串“清中”是一个词。而这显然是错误的!事实上我们知道 “清中”这个词在 base array 中压根不存在,但是此时的 base array 却不能为此提供更多的信息。
为了解决这些问题,双数组 Trie 树专门设计了一个 check 数组:
check array 与 base array 等长,它的作用是标识出 base array 中每个状态的前一个状态,以检验状态转移的正确性。
因此, 例树的 check array 应为:
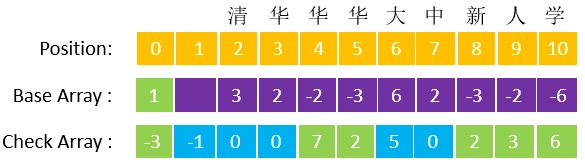
如图,check array 元素与 base array 一一对应,每个 check array 元素标明了base array 中相应节点的父节点位置,比如“清”节点对应的check[2]=0,说明“清”节点的父节点在 base array 的0 位(也即根节点)。对于上例,程序在找到位置9之后,会检验 check[9]==2,以检验该节点是否与“清”节点处于同一链路,由于check[9]!=2,那么就可以判定字符串“清中”并不在词典之中。
综上,check array 巧妙的利用了父子节点间双向关系的唯一性(公式化的表达就是base[s]+c=t & check[t]=s是唯一的,其中 s为父节点位置,t为子节点位置),避免了 base array 之中单向的状态转移关系所造成的歧义(公式化的表达就是base[s]+c=t)。
Trie 树的压缩
双数组 Trie 树虽然大幅改善了经典 Trie 树的空间浪费,但是由于冲突发生时,程序总是向后寻找空地址,导致数组不可避免的出现空置,因此空间上还是会有些浪费。另外, 随着节点的增加,冲突的产生几率也会越来越大,字典构建的时间因此越来越长,为了改善这些问题,有人想到对双数组 Trie 进行尾缀压缩,具体做法是:将非公共前缀的词尾合并为一个节点(tail 节点),以此大幅减少节点总数,从而改善树的构建速度;同时将合并的词尾单独存储在另一个数组之中(Tail array), 并通过 tail 节点的 base 值指向该数组的相应位置,以 {baby#, bachelor#, badge#, jar# }四词为例,其实现示意图如下: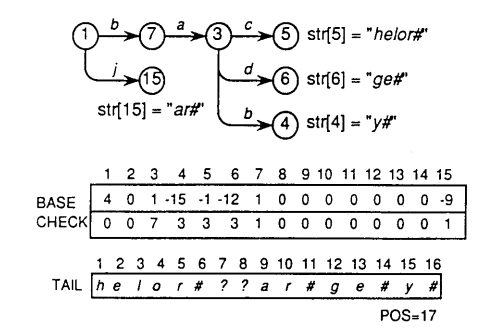
对于这种改进的效果,看一下别人家的测试就知道了:
速度
减少了base, check的状态数,以及冲突的概率,提高了插入的速度。在本地做了一个简单测试,随机插入长度1-100的随机串10w条,no tail的算法需120秒,而tail的算法只需19秒。
查询速度没有太大差别。内存
状态数的减少的开销大于存储tail的开销,节省了内存。对于10w条线上URL,匹配12456条前缀,内存消耗9M,而no tail的大约16M删除
能很方便的实现删除,只需将tail删除即可。
对于本文的例树,若采用tail 改进,其最终效果是这一子的:
总结
- Trie 树是一种以信息换时间的数据结构,其查询的复杂度为O(m)
- Trie 的单数组实现能够达到最佳的性能,但是其空间利用率极低,是典型的以空间换时间的实现
- Trie 树的哈希实现可以很好的平衡性能需求和空间开销,同时能够实现词典的实时更新
- Trie 树的双数组实现基本可以达到单数组实现的性能,同时能够大幅降低空间开销;但是其难以做到词典的实时更新
- 对双数组 Trie 进行 tail 改进可以明显改善词典的构建速度,同时进一步减少空间开销