一般设计网站的时候,会有问题发布或者是内容发布的功能,这些功能的有一个很重要的点在于如何实现敏感词过滤,要不然可能会有不良信息的发布,或者发布的内容中有夹杂可能会有恶意功能的代码片段,敏感词过滤的基本的算法是前缀树算法,前缀树也就是字典树,通过前缀树匹配可以加快敏感词匹配的速度。
首先是过滤HTML代码,在Spring中有直接的函数可以使用:1
question.setContent(HtmlUtils.htmlEscape(question.getContent()));
实现的功能就是将html的代码进行转义后显示出来,使其失效。举一个具体的例子:如果有一串字符串为xwabfabcff,敏感词为abc、bf、bc,若这个字符串中包含敏感词,则使用***代替敏感词,实现一个算法。
- 使用三个指针,指针1指向根节点,指针2指向字符串下标起始值,指针3指向字符串当前下标值。指针1为tempnode=rootnode,指针2为begin=0,指针3为position=0,创建stringbuffer sb来保存结果;
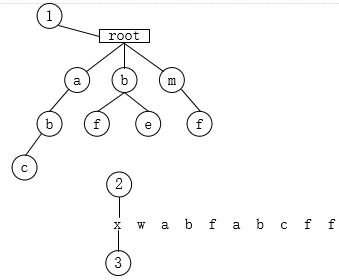
- 遍历x,tempnode未找到子节点x,将x保存到sb中,
1
begin=begin+1;position=begin,tempnode=rootnode;
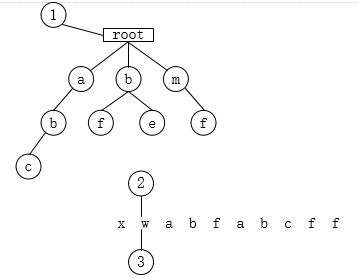
- 遍历w,tempnode未找到子节点w,将w保存到sb中,
1
begin=begin+1;position=begin,tempnode=rootnode;
同上
- 遍历a,tempnode找到子节点a,tempnode指向a节点,则position++;
- 遍历b,tempnode发现a节点下有b这个子节点,所以,tempnode指向b节点,则position++;
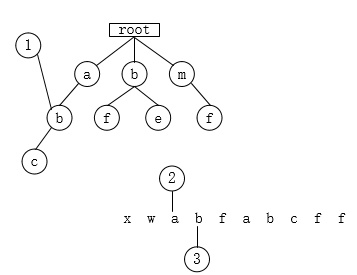
- 遍历f,tempnode发现b节点下没有f这个子节点,所以,代表以begin开头的字符串,不会有敏感字符,因此,将a存入sb中。
1
position=begin+1;bigin=position;tempnode=rootnode
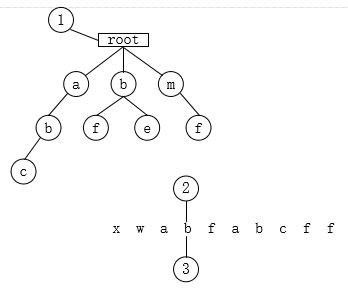
- 遍历b,tempnode找到子节点b,tempnode指向b节点,则position++;
- 遍历f,tempnode发现b节点下有f这个子节点,而且f值敏感词结尾标记,所以,打码。将**写入sb中,同时,begin=position+1;position=begin;tempnode=rootnode;
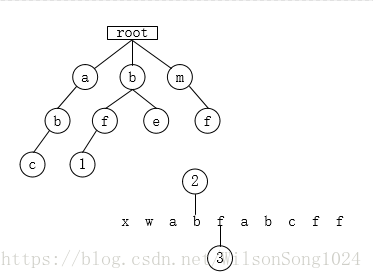
- 遍历a,tempnode找到子节点a,tempnode指向a节点,则position++;
- 遍历b,tempnode发现a节点下有b这个子节点,所以,tempnode指向b节点,则position++;
- 遍历c,tempnode发现b节点下有c这个子节点,而且c值敏感词结尾标记,所以,打码。将***写入sb中,同时,begin=position+1;position=begin;tempnode=rootnode;
- 遍历f,tempnode发现根节点下没有f这个节点,因此,将f存入sb中。position=begin+1;bigin=position;tempnode=rootnode;
- 遍历f,tempnode发现根节点下没有f这个节点,因此,将f存入sb中。position=begin+1;bigin=position;tempnode=rootnode;
因此,最后sb中为:xwa**ff;
这里每次是将position指向的字符挨个的与tempnode的子节点进行比较,因此,代码中的while条件应该是1
while (position < text.length()){}
同时,需要思考:
如果字符串为xwabfabcfb,则最后,begin指向b下标,position指向b下标,tempnode发现根节点下有b节点,因此position++;然后就退出循环了。而此时,sb中还只保存了xwa**f,
所以,我们在循环的最后,还要将最后一串字符串加进来。1
result.append(text.substring(begin));
完整的代码实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158package com.springboot.springboot.service;
import org.apache.commons.lang3.CharUtils;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Service;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
public class SensitiveService implements InitializingBean {
private static final Logger logger = LoggerFactory.getLogger(SensitiveService.class);
/**
* 默认敏感词替换符
*/
private static final String DEFAULT_REPLACEMENT = "敏感词";
private class TrieNode {
/**
* true 关键词的终结 ; false 继续
*/
private boolean end = false;
/**
* key下一个字符,value是对应的节点
*/
private Map<Character, TrieNode> subNodes = new HashMap<>();
/**
* 向指定位置添加节点树
*/
void addSubNode(Character key, TrieNode node) {
subNodes.put(key, node);
}
/**
* 获取下个节点
*/
TrieNode getSubNode(Character key) {
return subNodes.get(key);
}
boolean isKeywordEnd() {
return end;
}
void setKeywordEnd(boolean end) {
this.end = end;
}
public int getSubNodeCount() {
return subNodes.size();
}
}
/**
* 根节点
*/
private TrieNode rootNode = new TrieNode();
/**
* 判断是否是一个符号
*/
private boolean isSymbol(char c) {
int ic = (int) c;
// 0x2E80-0x9FFF 东亚文字范围
return !CharUtils.isAsciiAlphanumeric(c) && (ic < 0x2E80 || ic > 0x9FFF);
}
/**
* 过滤敏感词
*/
public String filter(String text) {
if (StringUtils.isBlank(text)) {
return text;
}
String replacement = DEFAULT_REPLACEMENT;
StringBuilder result = new StringBuilder();
TrieNode tempNode = rootNode; //指向树的根节点
int begin = 0; // 回滚数,指向字符串的指针,与树进行交互的
int position = 0; // 当前比较的位置,指向字符串
while (position < text.length()) {
char c = text.charAt(position);
// 空格直接跳过
if (isSymbol(c)) {
if (tempNode == rootNode) {
result.append(c);
++begin;
}
++position;
continue;
}
tempNode = tempNode.getSubNode(c);
// 当前位置的匹配结束
if (tempNode == null) {
// 以begin开始的字符串不存在敏感词
result.append(text.charAt(begin));
// 跳到下一个字符开始测试
position = begin + 1;
begin = position;
// 回到树初始节点
tempNode = rootNode;
} else if (tempNode.isKeywordEnd()) {
// 发现敏感词, 从begin到position的位置用replacement替换掉
result.append(replacement);
position = position + 1;
begin = position;
tempNode = rootNode;
} else {
++position;
}
}
//将最后一次的比较结果添加进去
result.append(text.substring(begin));
return result.toString();
}
private void addWord(String lineTxt) {
TrieNode tempNode = rootNode;
// 循环每个字节
for (int i = 0; i < lineTxt.length(); ++i) {
Character c = lineTxt.charAt(i);
// 过滤空格
if (isSymbol(c)) {
continue;
}
TrieNode node = tempNode.getSubNode(c);
if (node == null) { // 没初始化
node = new TrieNode();
tempNode.addSubNode(c, node);
}
tempNode = node;
if (i == lineTxt.length() - 1) {
// 关键词结束, 设置结束标志
tempNode.setKeywordEnd(true);
}
}
}
public void afterPropertiesSet() throws Exception {
rootNode = new TrieNode();
try {
InputStream is = Thread.currentThread().getContextClassLoader()
.getResourceAsStream("SensitiveWords.txt");
InputStreamReader read = new InputStreamReader(is);
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt;
while ((lineTxt = bufferedReader.readLine()) != null) {
lineTxt = lineTxt.trim();
addWord(lineTxt);
}
read.close();
} catch (Exception e) {
logger.error("读取敏感词文件失败" + e.getMessage());
}
}
public static void main(String[] argv) {
SensitiveService s = new SensitiveService();
s.addWord("色情");
s.addWord("赌博");
System.out.print(s.filter("你好赌博"));
}
}